Pytorch深度学习框架,加载图像数据集(这里以分类为例),通常都需要经过以下两个步骤:
1、定义数据集:torch以及torchvision中提供了多种方法来简化数据集定义的过程。
2、创建Dataloader数据加载器:通过torch.utils.data.Dataloader实例化数据加载迭代器,传 入自定义的数据集,并配置相关参数。
其中,第一个步骤定义数据集又包含多种实现方式:
1、torchvision.datasets.ImageFolder:用于加载标准的开源数据集。
2、torchvision.datasets.ImageFolder:从文件夹结构加载图像数据,自动生成标签。
3、torchvision.datasets.DatasetFolder:更通用的工具,适用于自定义图像数据集,其中,图像和标签不一定按文件夹结构组织。
4、torch.utils.data.Dataset:一个抽象基类,用户通过重写__init__、__len__、和 __getitem__ 方法以提供数据和标签。
第二个步骤,实例化数据加载迭代器 torch.utils.data.Dataloader 类,涉及到的主要参数:
None
在了解完数据集加载的两步骤后,其实主要变化的是第一步如何定义数据集。所以,接下来都是围绕不同的数据集定义方式,实现最终的数据加载。
目前,torchvision.datasets 库中已经收录了多种类型的数据集,一般都是各个图像处理领域内的开源标准数据集,如下列举了一些较为常见的数据集。
这种开源数据集的加载,还是非常简单的,因为大佬们都已经封装好方法了,直接调用API就实现了。这里以mnist手写数字识别数据集为例,代码如下。
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 数据转换
transform = transforms.Compose([transforms.ToTensor()])
# 加载 MNIST 数据集,这里设置了下载数据集
train_dataset = datasets.MNIST(root='mnist_datasets', train=True, download=True,transform=transform)
test_dataset = datasets.MNIST(root='mnist_datasets', train=False, download=True,transform=transform)
#打印dataset
print(train_dataset[0])
# 创建数据加载迭代器,传入数据集
train_loader = DataLoader(dataset=train_dataset, batch_size=256, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=256, shuffle=False)
# 使用加载器迭代输出数据
for images, labels in train_loader:
print("images:",images.shape)
print("labels",labels.shape)代码执行后的结果,首先在定义的root目录下,下载了mnist数据集 。

终端打印了train_dataset数据集中的第1个元素,前面也讲过,定义的数据集必须是可迭代的结构,也就是使用索引,可检索出其中的内容,其中内容的格式如下:
(tensor,label_index),tensor是图片,label_index是该图片对应的数字标签(模型中用到的标签,与现实中定义的标签不同,后续会讲)。
另外,终端也迭代输出了每一批次数据的形状,每一批次喂入的数据量 batch_size = 256 ,每一张图像形状(1,28,28),单通道的灰色图像,大小为28*28。

解释下,前面提到的模型标签与现实中真是标签。debug模式下,调试上面代码,可以看到定义的数据集train_dataset中的属性,其中:
classes:真实的标签
class_to_index:影射了真实标签与模型标签的关系,可以看到模型标签以阿拉伯数字命名,从0开始依次递增+1。
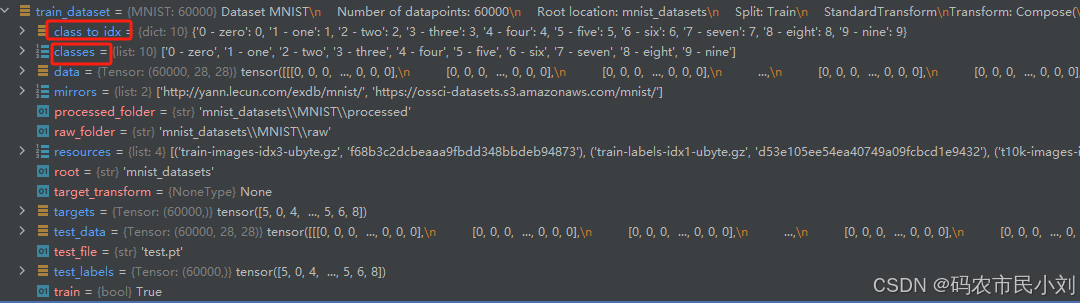
总结:训练时喂入的分类标签,是以阿拉伯数字,从0开始依次递增+1,这样的命名规则。所以,在模型训练和推理阶段,模型输出的标签依然是阿拉伯,这时候定义的class_to_index就有作用了,将模型推理出的阿拉伯数字标签转化为真正的类名。
torchvision.datasets.ImageFolder 主要用于从文件夹中加载图像数据集,指定根目录下的每一个子文件夹表示一个类别。该方法通常用于图像分类任务,并且可以很方便地使用Dataloader来加载批量数据。
文件夹的目录结构如下,root表示根目录,class_0和class_1是以类名命名的文件夹,里面分别包含属于该类的图像。
root/
class_0/
images1.jpg
images2.jpg
....
class_1/
images1.jpg
images2:jpg
....
....我测试的根目录 root 是mnist数据集中的train目录,共有10类。其中第10类,类名为 ”九“,是我特意修改的,同样也是为了验证真实标签与模型标签之间的关系。

这是第一类 0 文件夹下的数据,均为手写数字0 的图片。

接下里可直接使用代码加载该数据集。
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义数据预处理操作
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化
])
# 创建ImageFolder数据集,根目录用了绝对路径
dataset = datasets.ImageFolder(root='F:\Amode\datasets\mnist\train', transform=transform)
# 打印数据集中第一项
print(dataset[0])
# 创建DataLoader数据加载迭代器
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)
#按照常例,迭代遍历数据
for images,labels in data_loader:
print("images:",images.shape)
print("lables",labels)执行代码,终端打印信息,首先还是数据集中的第一项,内容格式仍然是:
(tensor,label_index)
同样,更简便的方式,大家用debug模式调试代码。
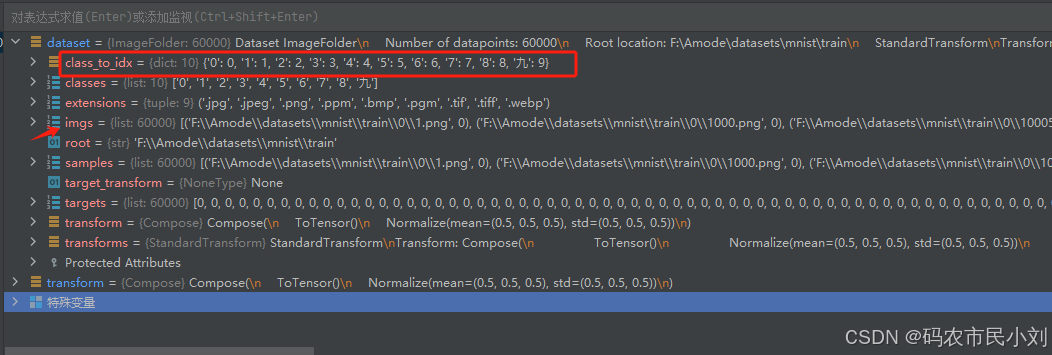
个人觉得,对于分类数据集,这种加载方式是非常容易和轻松的。前提是需要将数据集整理成固定的结构 。
torchvision.datasets.DatasetFolder 是一个比 ImageFolder 更灵活的类,而ImageFolder继承的父类就是它,它允许你自定义加载数据的方式,自定义数据集结构。
因为比较灵活百变,更难理解和掌握。接下来先了解下该方法的源码,初始化参数及重要属性。
这部分内容是初始化参数。
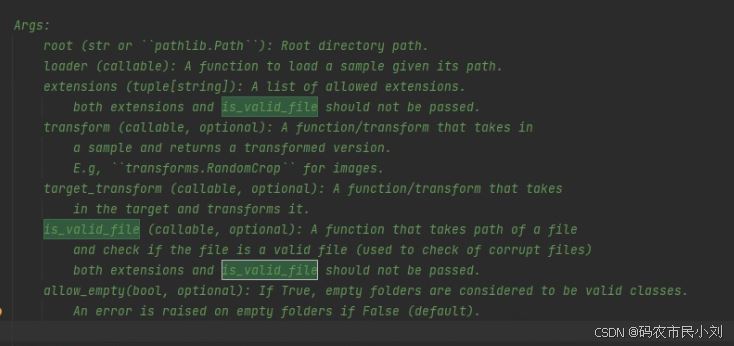
既然ImageFolder的父类就是它,可以先用它实现ImageFolder中要求的数据集目录结构(结构在第3部门有说明)。以下代码和ImagesFolde的r实现效果一致。
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from PIL import Image
#自定义的图像读取方式
def custom_load(path):
return Image.open(path).convert("RGB")
# 定义数据预处理操作
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化
])
# 创建ImageFolder数据集,根目录用了绝对路径
dataset = datasets.DatasetFolder(
root=r'F:\Amode\datasets\mnist\train',
loader= custom_load,
transform=transform,
extensions=("jpg","png")
)
# 打印数据集中第一项
print(dataset[0])
# 创建DataLoader数据加载迭代器
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)
#按照常例,迭代遍历数据
for images,labels in data_loader:
print("images:",images.shape)
print("lables",labels)假设,换种数据集的目录结构呢,这里举例一种比较常见的结构,如下图所示。
所有图片都在同一目录下,且图片文件名称以 label_name的格式命名,即标签在文件名中体现。

接下来是实现的代码,新定义了一个类,继承DatasetsFolder类,重新定义了父类中的find_class,make_dataset函数。想具体了解这两个函数的可点进父类源码中去看。
find_class:输入根目录root,输出classes(列表),所有的真实标签(str),输出class_to_idx(字典),键为真实标签,值为类别索引值。
make_dataset:输入仍是初始化那些参数;输出样本列表,格式为[(file_path,class_indx),.......]
import os
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from PIL import Image
#自定义的图像加载方式
def custom_load(path):
return Image.open(path).convert("RGB")
# 定义数据预处理操作
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Resize((null, 224)),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化
])
class custom_DatasetFolder(datasets.DatasetFolder):
#重写find_classes函数
def find_classes(self, directory):
"""
传参:根目录;
输出:classes = [] ,classes_to_idx = {class:index}
"""
lables = set()
lables_to_indexs = {}
#获取目录下文件列表
file_list = os.listdir(self.root)
#遍历文件列表
for f in file_list:
#从文件名中分离出标签
lable = f.split('_')[0]
#添加到集合中,集合不允许重复元素
lables.add(str(lable))
#生成真实标签label与类别索引class的映射字典
for i,l in enumerate(list(lables)):
lables_to_indexs[l] = int(i)
return list(lables),lables_to_indexs
def make_dataset(self,directory,class_to_idx,extensions,is_valid_file,allow_empty,):
"""
传参;
输出:sample[(path,class),......]
"""
#获取目录下的文件列表
file = os.listdir(directory)
samp = []
#遍历文件
for f in file:
#分离出标签和文件后缀
lab = f.split('_')[0]
sufix = f.split('.')[-1]
#文件后缀满足扩展要求
if sufix in extensions:
#根据标签找到类别class
cls = class_to_idx[lab]
#文件完整路径
file_path = os.path.join(directory,f)
#每个样本以(path,class)格式添加到列表中
samp.append((str(file_path),cls))
return samp
# 创建ImageFolder数据集,根目录用了绝对路径
dataset = custom_DatasetFolder(
root=r'F:\Amode\datasets\image_data',
loader= custom_load,
transform=transform,
extensions=("jpg","png")
)
# 打印数据集中第一项
print(dataset[0])
# 创建DataLoader数据加载迭代器
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)
#按照常例,迭代遍历数据
for images,labels in data_loader:
print("images:",images.shape)
print("lables",labels)任意结构的数据集,都可以使用基类DatasetFolder实现,主要还是通过覆盖上面两个函数,实现获取标签类别属性,以及样本的路径和类别,还有自定义的加载图片函数。
继上面内容,这是唯一一个使用torch,定义数据集的方式。

翻译一下上面的内容:
该类是一个抽象类,所有表示从键到数据样本映射的数据集都应继承此类。所有子类应重写 __getitem__ 方法,以支持根据给定的键获取数据样本。子类还可以选择性地重写 __len__ 方法,这通常会返回数据集的大小,torch.utils.data.Sampler 实现和 torch.utils.data.DataLoader 的默认选项都期望这个方法的存在。子类还可以选择性地实现 __getitems__ 方法,以加速批量样本的加载。该方法接受一个样本索引的列表,并返回这些样本的列表。
那什么叫抽象类呢?
抽象类是一种不能直接实例化的类,主要用于定义方法的基本结构和要求,其作为父类呢,通常让子类去继承它,并且在子类中必须实现这个抽象类中定义的方法,也就是具体的实现交给子类。
本节中用到的基类torch.utils.data.Datasets,需要实现以下三种方法。
__init__: 初始化数据集对象,通常在这里加载和处理数据。__len__: 返回数据集的大小(样本数量)。__getitem__: 根据给定的索引返回数据集中的样本和标签。这部分的演示代码,使用的是上一小节中的数据集 ,数据集和实现代码如下。
rom torch.utils.data import Dataset
from PIL import Image
import os
class CustomDataset(Dataset):
def __init__(self, image_folder, transform=None):
"""
Args:
image_folder : 图像所在文件夹的路径
transform : 应用于样本的转换操作
"""
self.image_folder = image_folder
self.transform = transform
self.class_to_idx = {}
self.image_files = [f for f in os.listdir(image_folder) if f.endswith('.jpg')]
self.__class_to_idx()
def __len__(self):
"""返回数据集中的样本数量"""
return len(self.image_files)
def __class_to_idx(self):
labels = set()
for file in os.listdir(self.image_folder):
if file.endswith('.jpg'):
label = file.split('_')[0]
labels.add(str(label))
for i,l in enumerate(labels):
self.class_to_idx[l] = int(i)
def __getitem__(self, idx):
"""
Args:
idx (int): 索引
Returns:
dict: 包含图像和标签的字典
"""
img_name = os.path.join(self.image_folder, self.image_files[idx])
image = Image.open(img_name).convert('RGB')
if self.transform:
image = self.transform(image)
# 标签从文件名中提取
lab_name = self.image_files[idx].split('_')[0]
label = self.class_to_idx[lab_name]
return image, label
from torch.utils.data import DataLoader
from torchvision import transforms
# 定义转换操作
transform = transforms.Compose([
transforms.Resize((null, 224)),
transforms.ToTensor()
])
# 实例化自定义数据集
dataset = CustomDataset(image_folder='F:\Amode\datasets\image_data', transform=transform)
# 创建 DataLoader
data_loader = DataLoader(dataset, batch_size=4, shuffle=True)
print(dataset[0])
# 使用 DataLoader 遍历数据
for images, labels in data_loader:
# 在这里进行训练或测试操作
print(images.size(), labels)以上就是Pytorch加载图像数据集的方法的详细内容,更多关于Pytorch加载图像数据集的资料请关注插件窝其它相关文章!