日常工作中,不可避免需要进行文件及内容的查找,替换操作,python的正则匹配无疑是专门针对改场景而出现的,灵活地运用可以极大地提高效率,下图是本文内容概览。
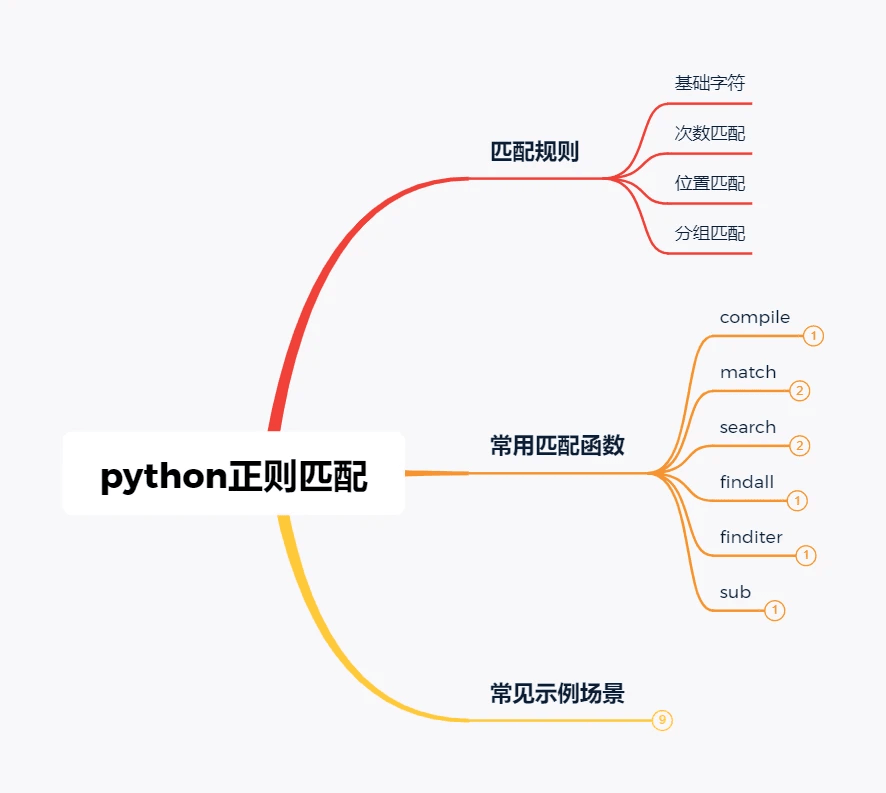
对于所有的正则匹配表达式,都可由4部分组成:基础字符,次数匹配,位置匹配,分组匹配,即
正则匹配表达式= 基础字符(必选)+次数匹配(可选)+位置匹配(可选)+分组匹配(可选)
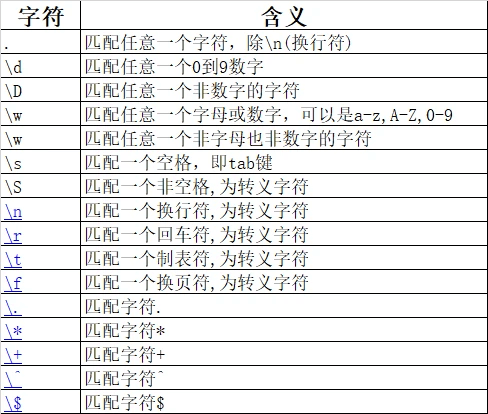
基础字符主要是对应与具体的匹配对象,常用的如下表,其中涉及有特殊含义的字符,如.,*,^,$等,如果要匹配该字符本身,需要使用转移符号"\"。
代码示例:
import re
string="lucky^ /696/ ^money \Healthy **"
pattern_num=re.compile("\d") #匹配数字
num=pattern_num.findall(string)
pattern_letter=re.compile("\w") #匹配字母或数字
letter=pattern_letter.findall(string)
pattern_blank=re.compile("\s") #匹配空格
blank=pattern_blank.findall(string)
pattern_slash=re.compile(r"\\") #匹配反斜杠\
slash=pattern_slash.findall(string)
pattern_tri=re.compile("\^") #匹配特殊字符^
tri=pattern_tri.findall(string)
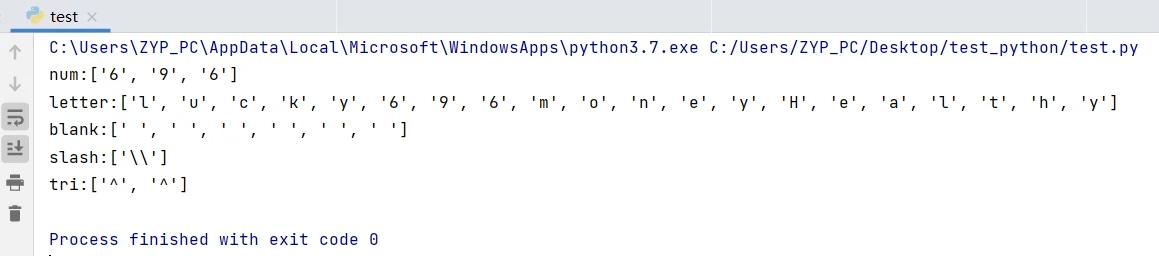
print("num:%s\nletter:%s\nblank:%s\nslash:%s\ntri:%s"%(num,letter,blank,slash,tri))查询结果,注意\s表示单个空格,连续两个空格是作为两个结果,单反斜杠\的结果slash表示用“\\”,如果使用print函数打印查看实际是单斜杠\
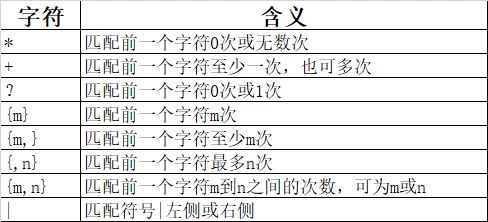
在设置了具体匹配字符后,还可以对字符匹配的数量进行限制,即在匹配字符后面加上匹配次数字符即可
代码示例
import re
string="lucky^ \/696/\ ^money// \Healthy 12**"
pattern_num=re.compile("\d+") #匹配至少1个数字
num=pattern_num.findall(string)
pattern_letter=re.compile("\w{4,5}") #匹配4-5个字母或数字
letter=pattern_letter.findall(string)
pattern_blank=re.compile("\s{3}") #匹配3个连续的空格
blank=pattern_blank.findall(string)
pattern_slash=re.compile(r"/{2,}") #匹配至少两个反斜杠//
slash=pattern_slash.findall(string)
pattern_tri=re.compile("\d|\^") #匹配数字或特殊字符^
tri=pattern_tri.findall(string)
print("num:%s\nletter:%s\nblank:%s\nslash:%s\ntri:%s"%(num,letter,blank,slash,tri))查询结果

同限制匹配字符的数量类似,可以设置匹配字符的位置,如指定开头或结尾的字符

代码示例
import re
string="luckyhappy happy-dog /happy, happy_test ^money Healthy 12**happy**"
pattern_head=re.compile("^luc") #匹配以luc开头的字符
head=pattern_head.findall(string) #匹配成功
print("head",head)
pattern_head1=re.compile("^money") #匹配以money开头的字符
head1=pattern_head1.findall(string) #匹配失败
print("head1",head1)
pattern_tail=re.compile("\*$") #匹配结尾为*的字符
tail=pattern_tail.findall(string) #匹配成功
print("tail",tail)
pattern_tail1=re.compile("money$") #匹配结尾为money的字符
tail1=pattern_tail1.findall(string) #匹配失败
print("tail1",tail1)
pattern_limit=re.compile(r"\bhappy\b") #匹配字符串中的单词happy,如果happy左右两侧都是字母数字下划线,注意前面需加r
limit=pattern_limit.findall(string) #匹配成功,其中luckyhappy和happy_test不属于匹配成功的对象
print("limit",limit)结果

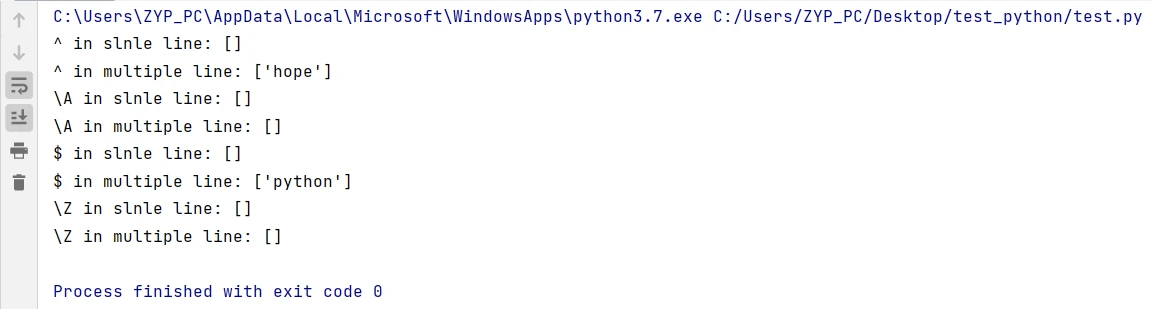
注意^和\A,$和\Z看似都匹配开头和结尾,但在多行模式下存在差异,如下例子
import re
str = "Have a wonderful\nhope in python\nstudy" #str内容为3行,\n表示换行
# 使用^
print("^ in slnle line:",re.findall("^hope", str)) # 默认单行模式,执照字符串的行首匹配,找不到匹配项
print("^ in multiple line:",re.findall("^hope", str, re.MULTILINE)) # 在多行模式下找到匹配项,会匹配其他行的行首
# 使用\A
print("\A in slnle line:",re.findall("\Ahope", str)) # 默认单行模式,执照字符串的行首匹配,找不到匹配项
print("\A in multiple line:",re.findall("\Ahope", str, re.MULTILINE)) # 在多行模式下,依然不会匹配其他行的行首
# 使用$
print("$ in slnle line:",re.findall("python$", str)) # 默认单行模式,执照字符串的行首匹配,找不到匹配项
print("$ in multiple line:",re.findall("python$", str, re.MULTILINE)) # 在多行模式下找到匹配项,会匹配其他行的行首
# 使用\Z
print("\Z in slnle line:",re.findall("python\Z", str)) # 默认单行模式,执照字符串的行首匹配,找不到匹配项
print("\Z in multiple line:",re.findall("python\Z", str, re.MULTILINE)) # 在多行模式下,依然不会匹配其他行的行首匹配结果

示例代码
import re
str = "Zyp Have a 626 wonderful hello hope in python *** study"
pattern=re.compile("(Zyp).*([0-9]{3}).*(\*{3})") #创建3个group查询
result=pattern.match(str)
print("All content:",result.group(0)) #group[0]为原始字符串
print("Name:",result.group(1)) #查找的结果下标从1开始
print("Value",result.group(2))
print("Count:",result.group(3))结果

前面内容已对匹配表达式进行了介绍,下面将介绍一些常用的查找函数,查找的条件也就是匹配表达式。主要有match,search,findall,finditer,sub,下表是它们之间的差异

compile函数不是匹配函数,主要是用于生成pattern对象,供匹配函数使用,好处是可以将该规则重复使用。
语法: re.compile(pattern, flags=0)
pattern : 匹配规则
flags : 标志位,默认为0,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。关于其中的flags,可配置如下值
示例代码
import re
str ="Zyp Have a 626 wonderful hello hope in python *** study"
str2="Hwq Have a 888 wonderful hello hope in python * study"
pattern=re.compile("(\w{3}).*([0-9]{3}).*(\*)") #创建3个group查询
result=pattern.match(str)
result2=pattern.match(str2) #直接复用pattern,直接修改用于匹配的对象
print("Name:",result.group(1),result2.group(1)) #查找的结果下标从1开始
print("Value",result.group(2),result2.group(2))
print("Count:",result.group(3),result2.group(3))匹配结果

match需要注意的是匹配是从行首位置开始,如果行首位置不存在匹配的结果,纵使后面存在可匹配的字符,依旧搜索不到,并且如果行首匹配成功,则直接返回结果,只进行一次匹配操作,不会继续对后面的进行匹配,
语法: re.match(pattern, string, flags=0)
pattern : 匹配规则
string : 用于正则匹配的字符串。
flags : 标志位,默认为0,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。代码示例
匹配结果,返回的结果为一个match对象

search作用与match类似,只进行一次匹配,但不会限制于在行首位置匹配,可在任意位置进行匹配,仍以match中的字符串示例
语法: re.search(pattern, string, flags=0)
pattern : 匹配规则
string : 用于正则匹配的字符串。
flags : 标志位,默认为0,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。代码示例
匹配结果,两个字符串str,str1都匹配到了符合规则的结果,返回的结果为一个match对象

findall从名称可看出是查询所有符合的匹配项,并且返回的结果类型为列表,仍以相同的例子为例,多加了一个1314
语法: re.findall(pattern, string, flags=0)
pattern : 匹配规则
string : 用于正则匹配的字符串。
flags : 标志位,默认为0,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。示例代码
匹配结果,两个字符串的查询结果一致

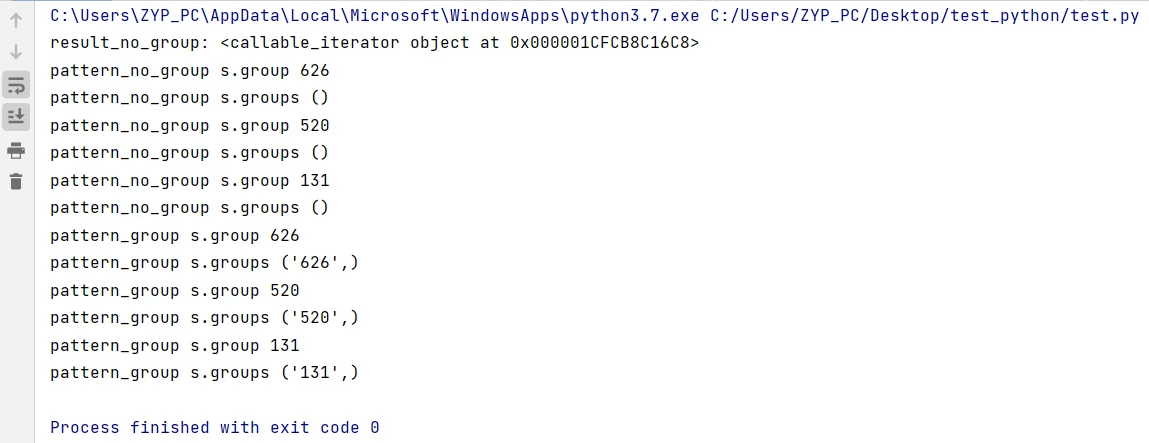
finditer作用与findall相同,也是查询所有符合条件的结果,区别是返回的结果为迭代器,而不是列表。同时迭代表结果的查看可通过函数group或groups进行查看,但groups查看结果,必须匹配规则pattern中设置了分组形式,否则查找的内容为空元组。
语法: re.finditer(pattern, string, flags=0)
pattern : 匹配规则
string : 用于正则匹配的字符串。
flags : 标志位,默认为0,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。示例代码
匹配结果
语法: re.sub(pattern, repl, string, count=0, flags=0)
pattern : 匹配规则
repl : 用于替换匹配结果的新字符串。
string : 用于正则匹配的字符串。
count : 设置匹配后的替换次数,默认 0 表示替换所有的匹配结果。
flags : 编译时用的匹配模式。
代码示例
import re
str ="Zyp Have a 626 wonderful hello hope 520 in python 1314*** study" #str存在2个3位,1个4位的数字,
pattern=re.compile("[0-9]{3}") #匹配一个3位的数字
result=re.sub(pattern,"999",str,count=2) #对于查询到的3位数字用999替换,只替换2次
print("result:",result)替换结果,原先3位的数字前面2个都已替换位999,因只替换2次,第3个1314不进行替换

下面将针对一些常用的场景提供对应的匹配规则
正则表达式 含义
[3] 匹配数字“3”,即指定匹配的具体数字
[c] 匹配字母“c”,即指定匹配的具体字符
[0-9] 匹配一个数字
[^0-9] 匹配一个除0-9外的字符
[a-z] 匹配一个小写字母
[A-Z] 匹配一个大写字母
[a-zA-Z] 匹配一个字母
[^a-z] 匹配一个非小写字母的字符
^\d{4}-\d{1,2}-\d{1,2} 匹配以“-”形式分隔的日期,如2024-5-2
\d{18}|\d{17}[X]$ 匹配出身份证号码
\d+\.\d+\.\d+\.\d+ 匹配IP地址
^[A-Za-z0-9\.\+_-]+@[A-Za-z0-9\._-]+\.[a-zA-Z]*$ 匹配电子邮箱到此这篇关于Python正则匹配的文章就介绍到这了,更多相关Python正则匹配内容请搜索插件窝以前的文章或继续浏览下面的相关文章希望大家以后多多支持插件窝!