在互联网中大型项目中,读写分离应该是我们小伙伴经常听说的,这个主要解决大流量请求时,提高系统的吞吐量。因为绝大部分互联网产品都是读多写少,大部分都是读请求,很小部分是写请求。
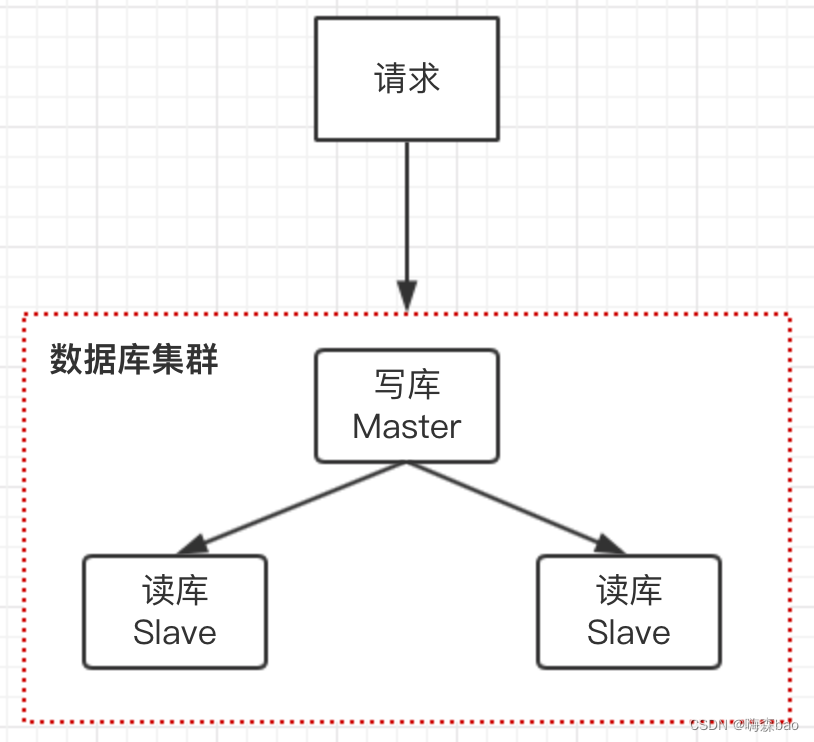
1)一个主库负责写请求,更新数据
2)两个从库负责读请求,可以提高系统吞吐量
3)主库和从库之间同步数据
为什么产生数据不一致

上图中业务流程
1)写请求A进行数据更新,但写库还没有来得及把更新的数据更新到读库
2)读请求B进行数据查询,请求B是访问的读库,获取的是旧值
3)因为写库和读库之间存在同步延迟,导致数据在不同库中不一致
我们一般用的数据库是mysql和oracle,mysql是我们互联网项目都会用到的,oracle一般大公司用的比较多(很贵啊)。
我们分析一下问题,原因就是在主库(写库)与从库(读库)之间数据同步延迟导致,mysql中有全同步复制机制、半同步复制、异步复制三种复制方案(小伙伴可以自行去了解)。
mysql全同步复制
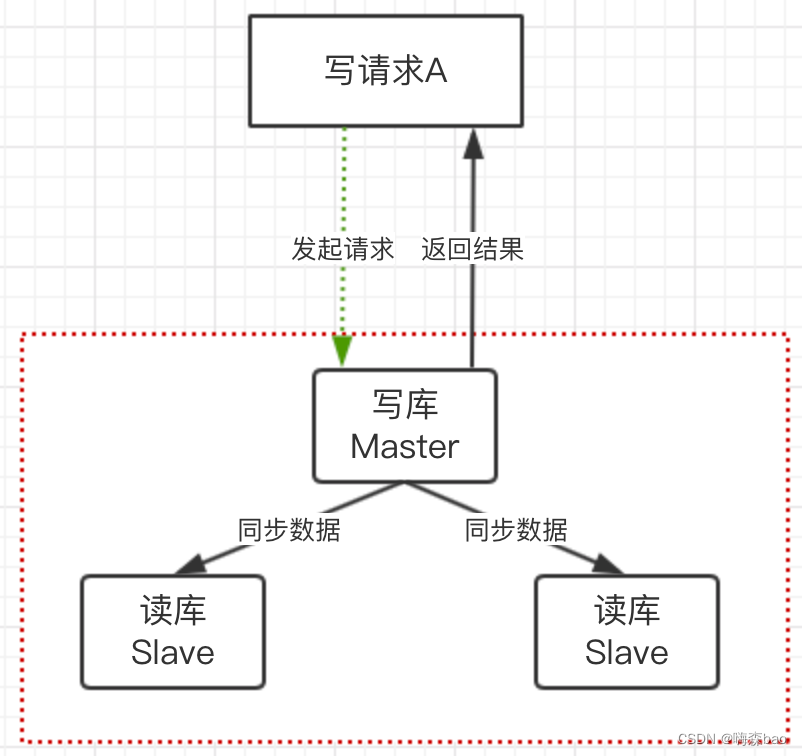
全同步复制,当A提交更新请求主库事务之后,不是立即返回,而是等到所有的从库节点必须收到、APPLY并且提交这些事务,主库线程才返回请求A结果,才能做后续操作。这样就解决了数据同步延迟的问题。
问题:但这个同步方案严重的问题就是写请求耗时会很长,而且会随者从库数量增加,耗时也会增加。(不推荐)
oracle共享存储
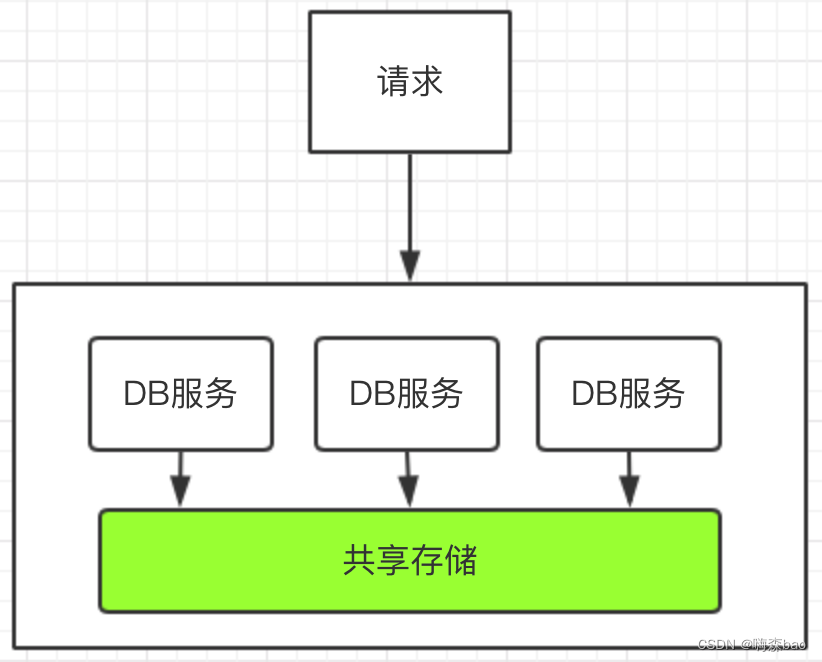
上图采用了oracle RAC方案,DB服务其实就代表一个应用服务,所有的数据存储在同一个地方,所有就不存在数据同步这个问题。当然这个部署方案不是我们严格意义上面的读写分离,存储是独立的。
我们设计任何架构方案,都要围绕着业务,如果业务能够接受可以不解决;其实很多互联网产品都有短时间的数据不一致问题。如:58同城,美团,贴吧等。
但有些场景是不允许的。如

上图中:
1)用户写了一篇文章,点击保存按钮
2)系统执行保存方法,提示用户保存成功
3)保存成功后一般系统就会立即跳转到文章列表,按照时间倒序,最新的文章排在第一个,这个业务是很正常的,让用户可以看到自己的文章列表
4)这样就是调用获取文章列表的方法getArticleList,但这个方法是读请求,走的是从库。
5)如果出现主库和从库同步延迟,就出现了不一致。
这个方案是:一些业务的操作是有前端页面的,不管是网页或App等。此方案的思路就是把之前保存的文章缓存到客户端,在用户到文章列表时,数据的组成就是(客户端缓存文章 + 后端读库返回的文章数据)。客户端要做的就是缓存要设置一个时间(这个缓存时间,可以预估主库同步到从库的时间延迟);以及要做文章去重,防止读库已经同步完成,客户端缓存没有过期。
问题:客户端逻辑复杂;客户端有缓存数据大小的限制,不能保存大数据。列表分页处理复杂。
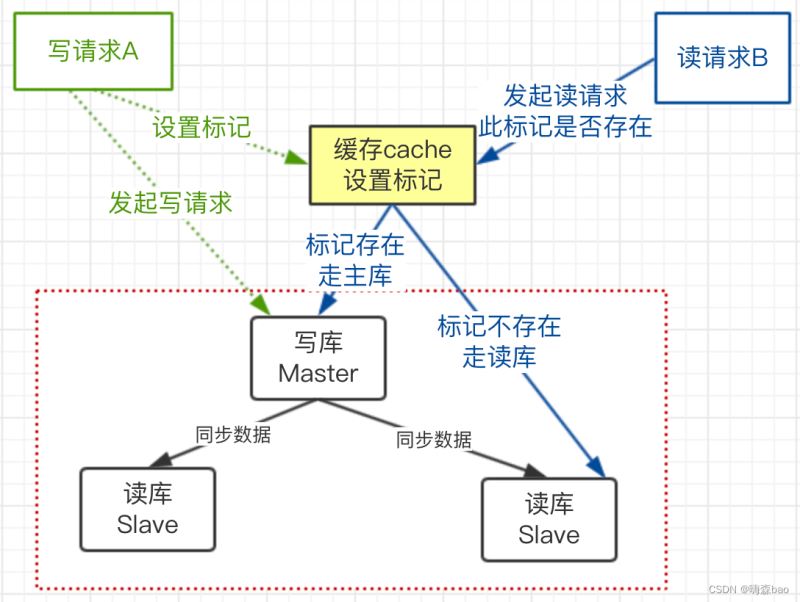
上图流程:
1)A发起写请求,更新了主库,但在缓存中设置一个标记,代表此数据已经更新,标记格式(业务代号:数据库:表:主键ID)根据自己业务场景。
2)设置此标记,要加上过期时间,可以为预估的主库和从库同步延迟的时间
3)B发起读请求的时候,先判断此请求的业务在缓存中有没有更新标记
4)如果存在标记,走主库;如果没有走从库。
这个方案就有效了解决了数据不一致的问题。
但这个方案会有个严重的问题,也就是每次的读请求都要到缓存中去判断是否存在缓存标记,如果是单机部署用的是jvm缓存,对性能还好;但如果是集群部署缓存肯定用redis,每次读都要和redis进行交互,这样肯定会影响系统吞吐量。
那怎么办?怎么办?继续往下看
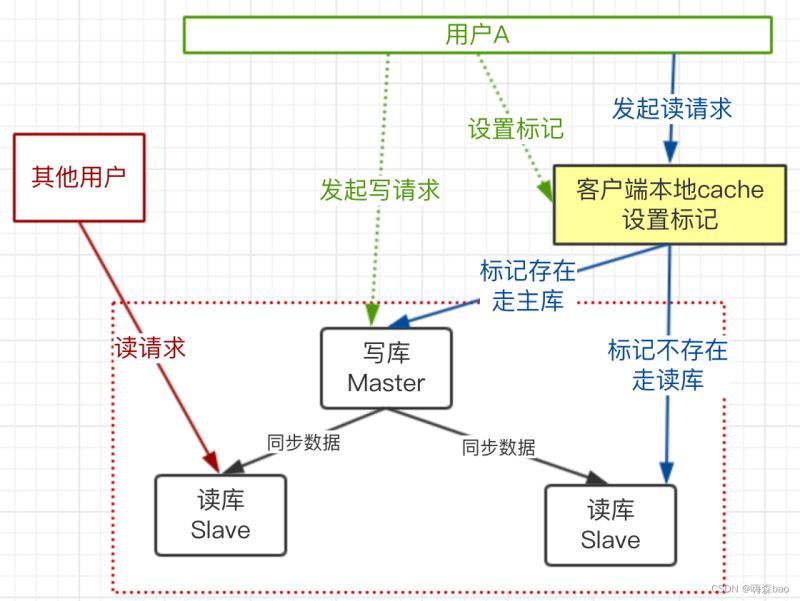
上图流程:
1)用户A发起写请求,更新了主库,并在客户端设置标记,过期时间,如:cookies
2)用户A再发起读请求时,带上这个本地标记在后端
3)后端在处理请求时,获取请求传过来的数据,看有没有这个标记(如:cookies)
4)有这个业务标记,走主库;没有走从库。
这个方案就保证了用户A的读请求肯定是数据一致的,而且没有性能问题,因为标记是本地客户端传过去的。
但有写小伙伴就会问那其他用户在本地客户端是没有这个标记的,他们走的就是从库了。那其他用户不就看不到这个数据了吗?说的对,其他用户是看不到,但看不到的时间很短,过个1~10秒就能够看到。
但这个方案解决了当前用户的数据一致性的问题,如上面举的例子,写文章,然后到文章列表,本用户是能够看到的。其他用户暂时看不到是没有关系的。还是那句话,脱离业务的方案是耍流氓。(推荐)
其实在真实业务中,尤其互联网项目中,数据短时间的不一致时能够接受的。就像怎么解决DB读写分离,导致数据不一致问题?中提到的本地缓存标记法,保证了本用户数据一致,其他用户可暂时不一致,但最终是一致的这个思路。我们可以设置一个延迟消息,如下图
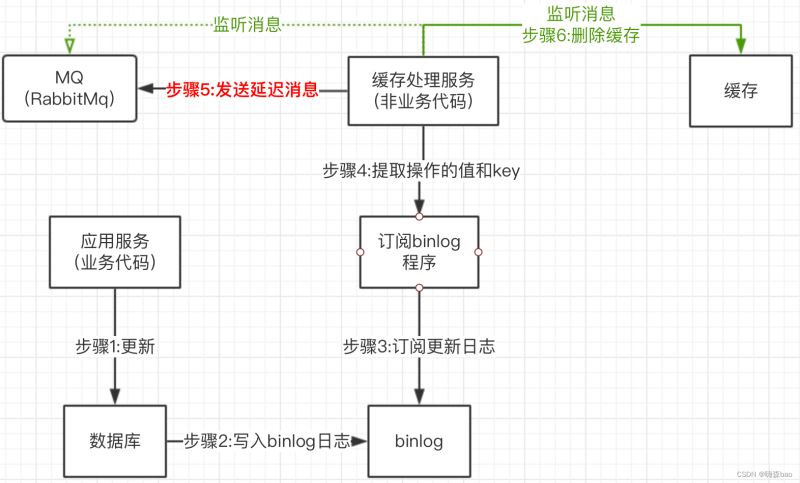
流程:
1)在订阅到binlog更新日志时,先不删除缓存,而是投递一个延迟消息(如:延迟10秒的消息,就是过10秒此消息才会被消费者监听到,从而被消费)
2)延迟消息的延迟时间,设置为主库与从库的数据同步延迟的时间,可自行预估
3)监听到延迟消息,在删除缓存。
这个方案的特点就是读请求会在延迟时间内读取到的是旧值,等到延迟时间一过,取到的就是新值。这个业务在互联网产品中是允许的。
如果要保证本用户(更新数据的用户)一定读到的是新值,这边可以采用本地缓存标记方案,直接从主数据库读取,读取到数据后,可以把新值设置到缓存中,这样就保证了数据一致性。
在方案一中,其他用户的读请求会有暂时间读取到的是旧值,如何缩短时间?其实是有一个方案,就是让更新用户再次发起读请求,也就是在方案一最后提到的
1)更新用户再次发起读请求,根据本地缓存标记,直接走主数据库,读取的肯定是新值,
2)再把这个新值设置到缓存中。这样就保证了缓存中的是新值,虽然从库还没有不同完成,但缓存中已经是新值了。
3)最后从库同步数据完成,值就达到了一致性
以上就是MySQL处理DB读写分离数据不一致问题的方案的详细内容,更多关于MySQL DB读写分离数据不一致的资料请关注插件窝其它相关文章!