行级锁的类型主要有三类:
Record Lock 称为记录锁,锁住的是一条记录。而且记录锁是有 S 锁和 X 锁之分的:
举个例子,当一个事务执行了下面这条语句:
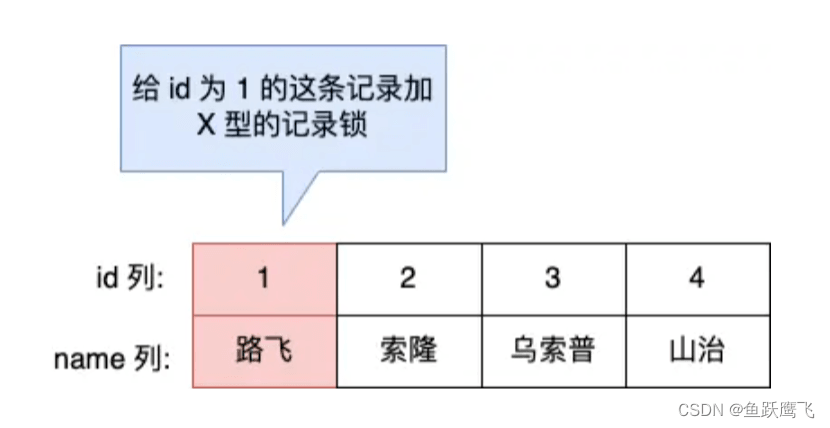
mysql > begin; mysql > select * from t_test where id = 1 for update;
就是对 t_test 表中主键 id 为 1 的这条记录加上 X 型的记录锁,这样其他事务就无法对这条记录进行修改了。
当事务执行 commit 后,事务过程中生成的锁都会被释放。
Gap Lock 称为间隙锁,只存在于可重复读隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。
假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生。
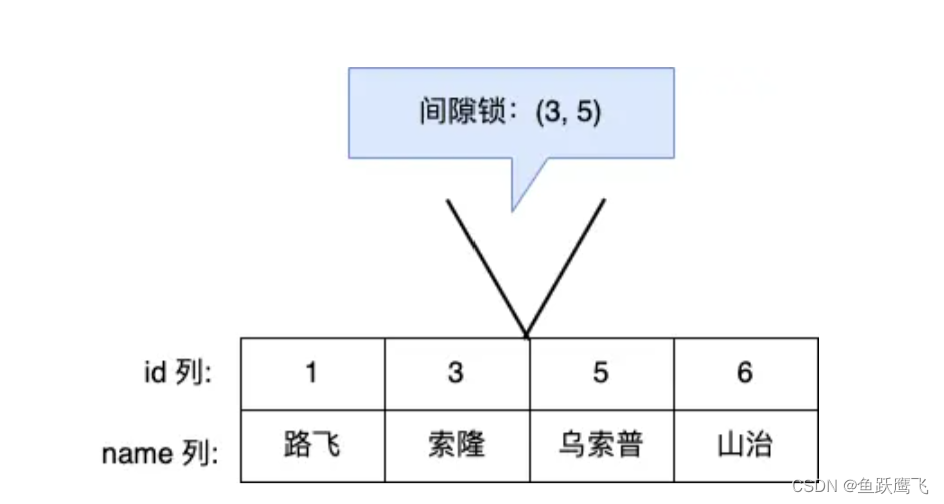
间隙锁虽然存在 X 型间隙锁和 S 型间隙锁,但是并没有什么区别,间隙锁之间是兼容的,即两个事务可以同时持有包含共同间隙范围的间隙锁,并不存在互斥关系,因为间隙锁的目的是防止插入幻影记录而提出的。
Next-Key Lock 称为临键锁,是 Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。既然是组合,那我们可以理解为只有Gap Lock存在的情况下才会有Next-Key Lock
假设,表中有一个范围 id 为(3,5] 的 next-key lock,那么其他事务即不能插入 id = 4 记录,也不能修改 id = 5 这条记录。
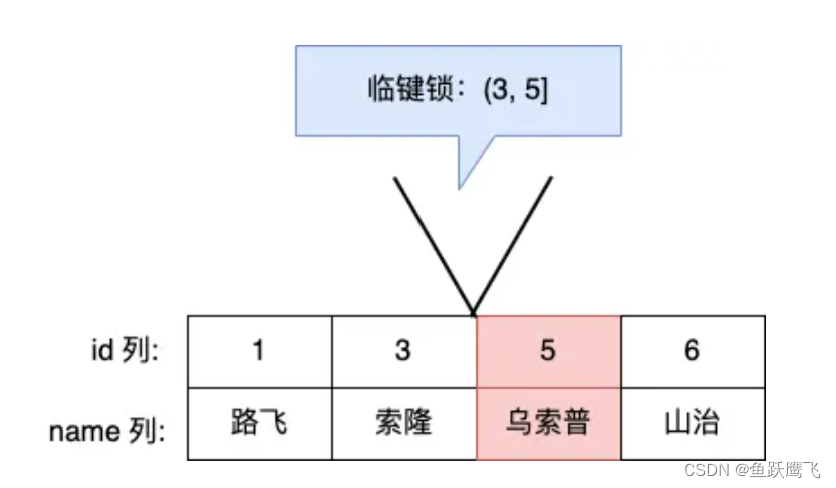
所以,next-key lock 即能保护该记录,又能阻止其他事务将新纪录插入到被保护记录前面的间隙中。
next-key lock 是包含间隙锁+记录锁的,如果一个事务获取了 X 型的 next-key lock,那么另外一个事务在获取相同范围的 X 型的 next-key lock 时,是会被阻塞的。
比如,一个事务持有了范围为 (null, 10] 的 X 型的 next-key lock,那么另外一个事务在获取相同范围的 X 型的 next-key lock 时,就会被阻塞。
虽然相同范围的间隙锁是多个事务相互兼容的,但对于记录锁,我们是要考虑 X 型与 S 型关系,X 型的记录锁与 X 型的记录锁是冲突的。
一个事务在插入一条记录的时候,需要判断插入位置是否已被其他事务加了间隙锁(next-key lock 也包含间隙锁)。
如果有的话,插入操作就会发生阻塞,直到拥有间隙锁的那个事务提交为止(释放间隙锁的时刻),在此期间会生成一个插入意向锁,表明有事务想在某个区间插入新记录,但是现在处于等待状态。
举个例子,假设事务 A 已经对表加了一个范围 id 为(3,5)间隙锁。

当事务 A 还没提交的时候,事务 B 向该表插入一条 id = 4 的新记录,这时会判断到插入的位置已经被事务 A 加了间隙锁,于是事物 B 会生成一个插入意向锁,然后将锁的状态设置为等待状态(PS:MySQL 加锁时,是先生成锁结构,然后设置锁的状态,如果锁状态是等待状态,并不是意味着事务成功获取到了锁,只有当锁状态为正常状态时,才代表事务成功获取到了锁),此时事务 B 就会发生阻塞,直到事务 A 提交了事务。
插入意向锁名字虽然有意向锁,但是它并不是意向锁,它是一种特殊的间隙锁,属于行级别锁。
如果说间隙锁锁住的是一个区间,那么「插入意向锁」锁住的就是一个点。因而从这个角度来说,插入意向锁确实是一种特殊的间隙锁。
插入意向锁与间隙锁的另一个非常重要的差别是:尽管「插入意向锁」也属于间隙锁,但两个事务却不能在同一时间内,一个拥有间隙锁,另一个拥有该间隙区间内的插入意向锁(当然,插入意向锁如果不在间隙锁区间内则是可以的)。
行级锁加锁规则比较复杂,不同的场景,加锁的形式是不同的。
加锁的对象是索引,加锁的基本单位是 next-key lock,它是由记录锁和间隙锁组合而成的,next-key lock 是前开后闭区间,而间隙锁是前开后开区间。
但是,next-key lock 在一些场景下会退化成记录锁或间隙锁。
那到底是什么场景呢?总结一句,在能使用记录锁或者间隙锁就能避免幻读现象的场景下, next-key lock 就会退化成记录锁或间隙锁。
这次会以下面这个表结构来进行实验说明:
CREATE TABLE `user` ( `id` bigint NOT NULL AUTO_INCREMENT, `name` varchar(30) COLLATE utf8mb4_unicode_ci NOT NULL, `age` int NOT NULL, PRIMARY KEY (`id`), KEY `index_age` (`age`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
其中,id 是主键索引(唯一索引),age 是普通索引(非唯一索引),name 是普通的列。
表中的有这些行记录:
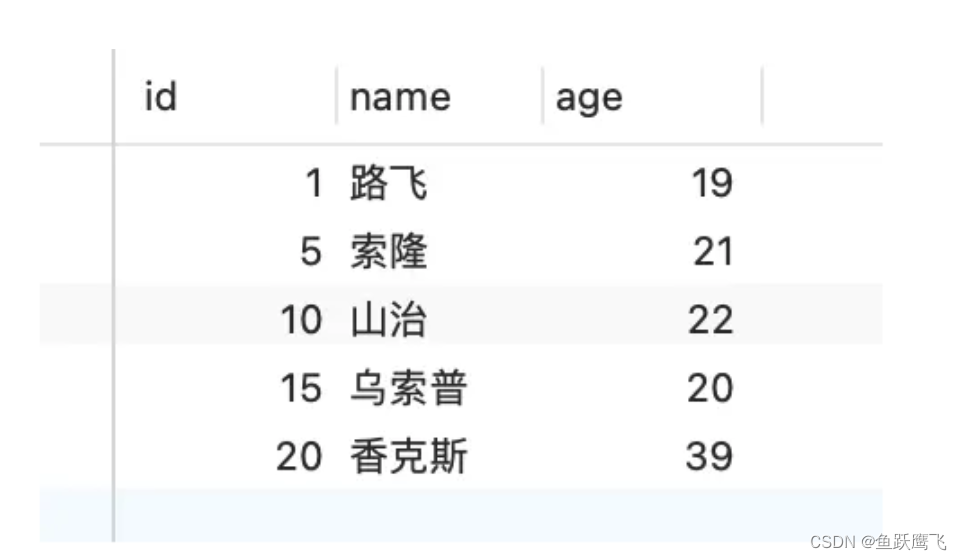
这次实验环境的 MySQL 版本是 8.0.26,隔离级别是「可重复读」。
不同版本的加锁规则可能是不同的,但是大体上是相同的。
当我们用唯一索引进行等值查询的时候,查询的记录存不存在,加锁的规则也会不同:
TIP
我本篇文章的「唯一索引」是用「主键索引」作为案例说明的,加锁只加在主键索引项上。
然后,很多同学误以为如果是二级索引的「唯一索引」,加锁也是只加在二级索引项上。
其实这是不对的,所以这里特此说明下,如果是用二级索引(不管是不是非唯一索引,还是唯一索引)进行锁定读查询的时候,除了会对二级索引项加行级锁(如果是唯一索引的二级索引,加锁规则和主键索引的案例相同),而且还会对查询到的记录的主键索引项上加「记录锁」。
在文章的「非唯一索引」的案例中,我就是用二级索引作为例子,在后面的章节我有说明,对二级索引进行锁定读查询的时候,因为存在两个索引(二级索引和主键索引),所以两个索引都会加锁。
接下里用两个案例来说明。
1、记录存在的情况
假设事务 A 执行了这条等值查询语句,查询的记录是「存在」于表中的。
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where id = 1 for update; +----+--------+-----+ | id | name | age | +----+--------+-----+ | 1 | 路飞 | 19 | +----+--------+-----+ 1 row in set (0.02 sec)
那么,事务 A 会为 id 为 1 的这条记录就会加上 X 型的记录锁。
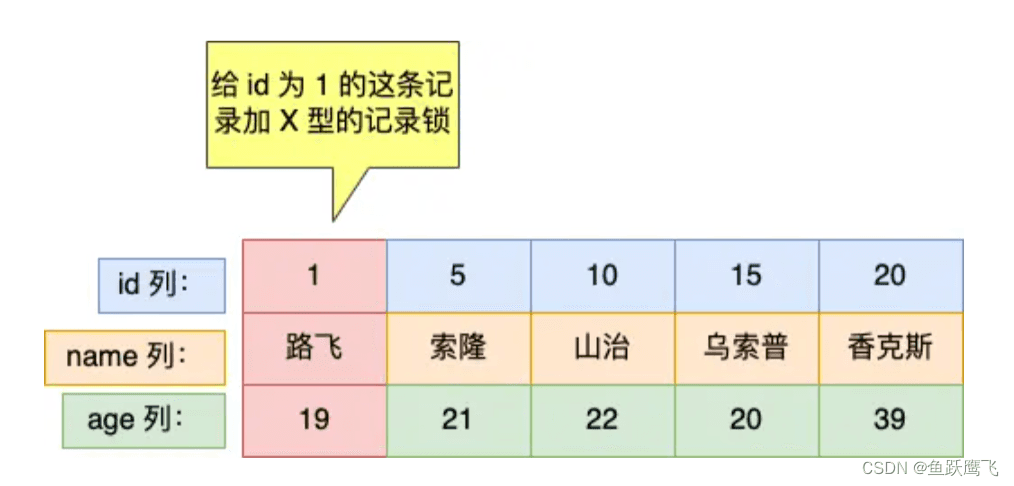
接下来,如果有其他事务,对 id 为 1 的记录进行更新或者删除操作的话,这些操作都会被阻塞,因为更新或者删除操作也会对记录加 X 型的记录锁,而 X 锁和 X 锁之间是互斥关系。
比如,下面这个例子:
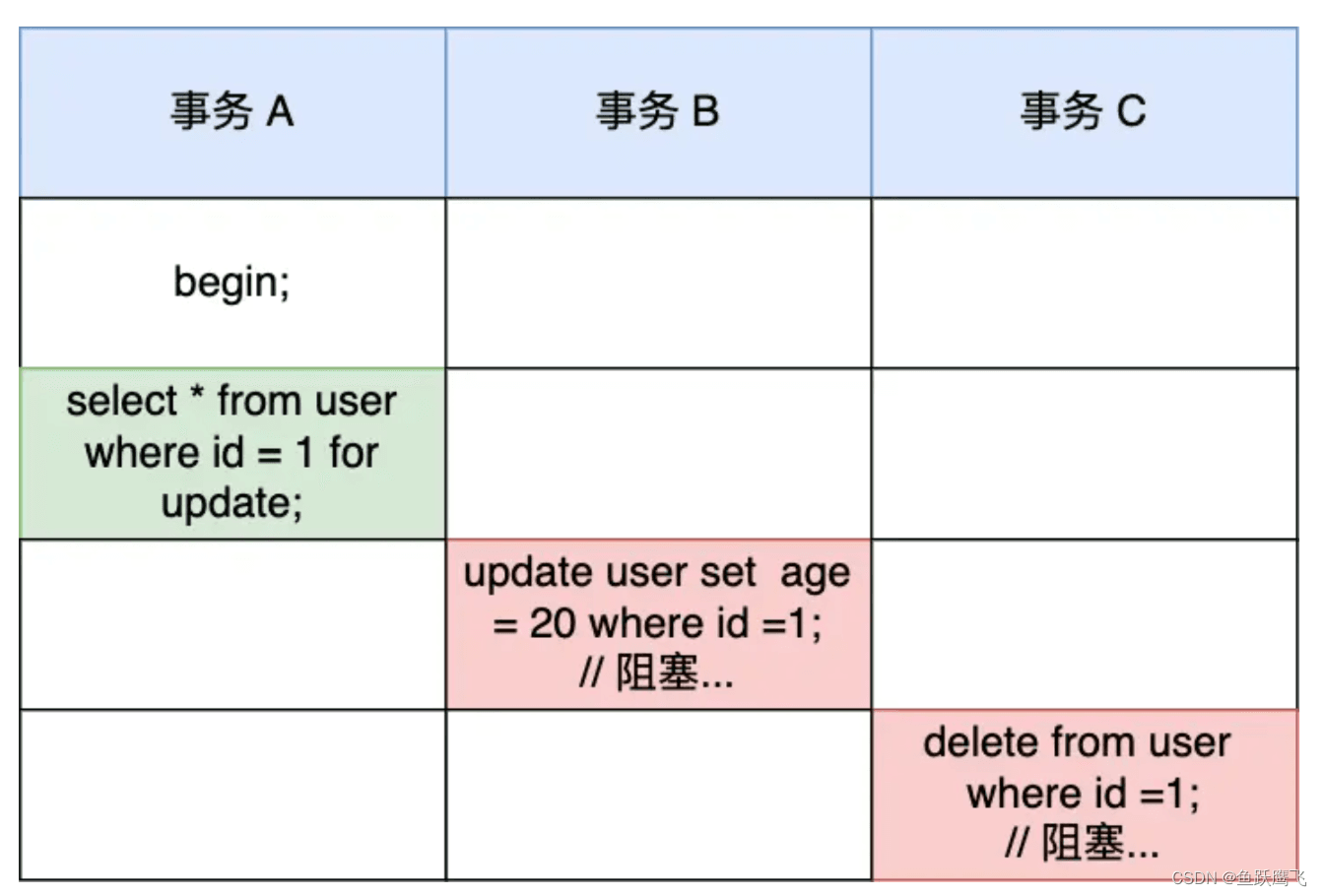
因为事务 A 对 id = 1的记录加了 X 型的记录锁,所以事务 B 在修改 id=1 的记录时会被阻塞,事务 C 在删除 id=1 的记录时也会被阻塞。
有什么命令可以分析加了什么锁?
我们可以通过 select * from performance_schema.data_locks\G; 这条语句,查看事务执行 SQL 过程中加了什么锁。
我们以前面的事务 A 作为例子,分析下下它加了什么锁。
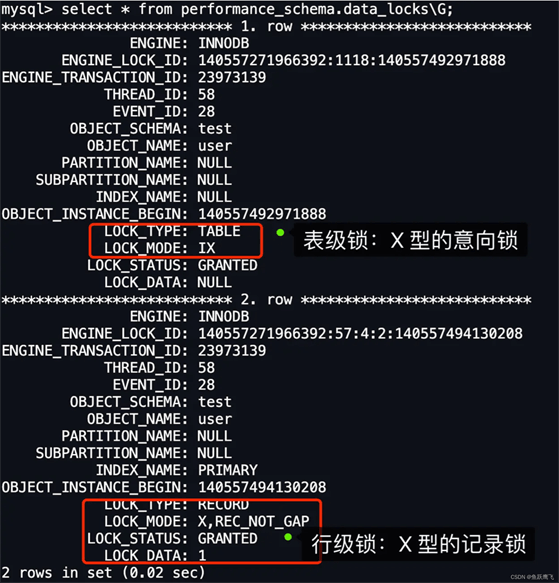
从上图可以看到,共加了两个锁,分别是:
这里我们重点关注行级锁,图中 LOCK_TYPE 中的 RECORD 表示行级锁,而不是记录锁的意思。
通过 LOCK_MODE 可以确认是 next-key 锁,还是间隙锁,还是记录锁:
X,说明是 next-key 锁;X, REC_NOT_GAP,说明是记录锁;X, GAP,说明是间隙锁;因此,**此时事务 A 在 id = 1 记录的主键索引上加的是记录锁,锁住的范围是 id 为 1 的这条记录。**这样其他事务就无法对 id 为 1 的这条记录进行更新和删除操作了。
从这里我们也可以得知,加锁的对象是针对索引,因为这里查询语句扫描的 B+ 树是聚簇索引树,即主键索引树,所以是对主键索引加锁。将对应记录的主键索引加 记录锁后,就意味着其他事务无法对该记录进行更新和删除操作了。
为什么唯一索引等值查询并且查询记录存在的场景下,该记录的索引中的 next-key lock 会退化成记录锁?
原因就是在唯一索引等值查询并且查询记录存在的场景下,仅靠记录锁也能避免幻读的问题。
幻读的定义就是,当一个事务前后两次查询的结果集,不相同时,就认为发生幻读。所以,要避免幻读就是避免结果集某一条记录被其他事务删除,或者有其他事务插入了一条新记录,这样前后两次查询的结果集就不会出现不相同的情况。
由于主键具有唯一性,所以其他事务插入 id = 1 的时候,会因为主键冲突,导致无法插入 id = 1 的新记录。这样事务 A 在多次查询 id = 1 的记录的时候,不会出现前后两次查询的结果集不同,也就避免了幻读的问题。
由于对 id = 1 加了记录锁,其他事务无法删除该记录,这样事务 A 在多次查询 id = 1 的记录的时候,不会出现前后两次查询的结果集不同,也就避免了幻读的问题。
2、记录不存在的情况
假设事务 A 执行了这条等值查询语句,查询的记录是「不存在」于表中的。
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where id = 2 for update; Empty set (0.03 sec)
接下来,通过 select * from performance_schema.data_locks\G; 这条语句,查看事务执行 SQL 过程中加了什么锁。
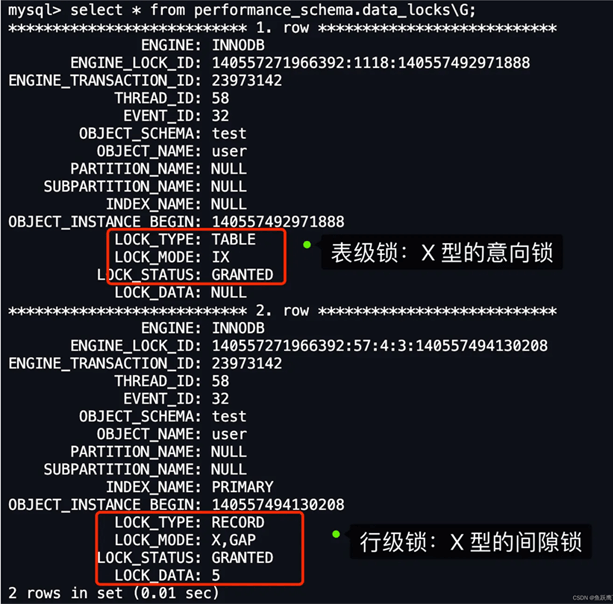
从上图可以看到,共加了两个锁,分别是:
因此,此时事务 A 在 id = 5 记录的主键索引上加的是间隙锁,锁住的范围是 (null, 5)。
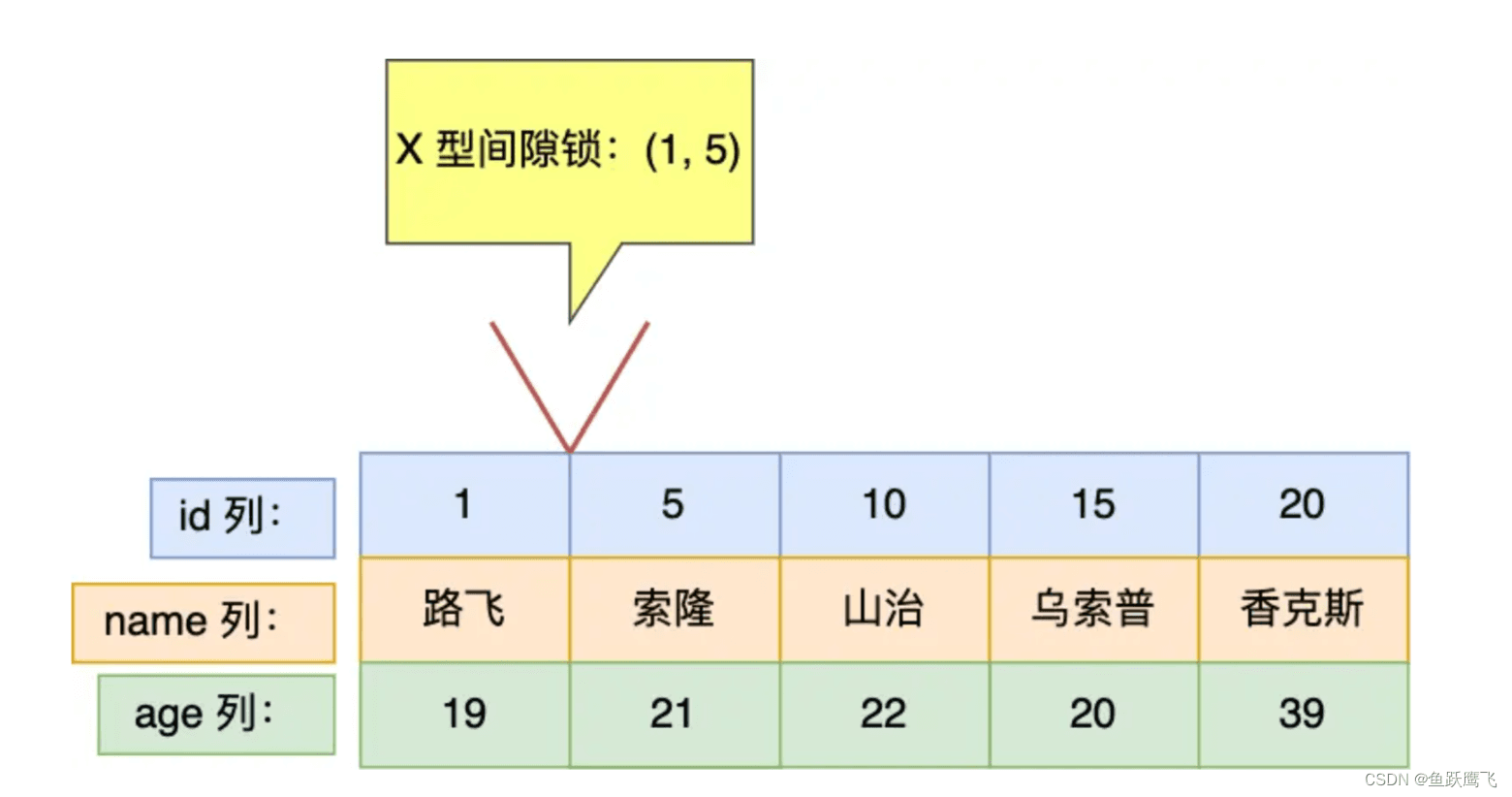
接下来,如果有其他事务插入 id 值为 2、3、4 这一些记录的话,这些插入语句都会发生阻塞。
注意,如果其他事务插入的 id = 1 或者 id = 5 的记录话,并不会发生阻塞,而是报主键冲突的错误,因为表中已经存在 id = 1 和 id = 5 的记录了。
比如,下面这个例子:
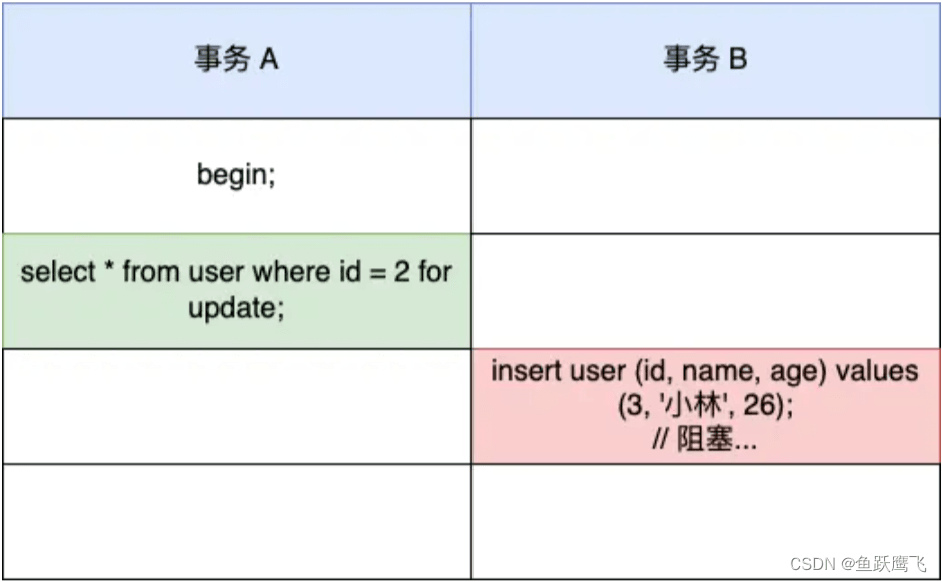
因为事务 A 在 id = 5 记录的主键索引上加了范围为 (null, 5) 的 X 型间隙锁,所以事务 B 在插入一条 id 为 3 的记录时会被阻塞住,即无法插入 id = 3 的记录。
间隙锁的范围
(null, 5),是怎么确定的?
根据我的经验,如果 LOCK_MODE 是 next-key 锁或者间隙锁,那么 LOCK_DATA 就表示锁的范围「右边界」,此次的事务 A 的 LOCK_DATA 是 5。
然后锁范围的「左边界」是表中 id 为 5 的上一条记录的 id 值,即 1。
因此,间隙锁的范围(null, 5)。
为什么唯一索引等值查询并且查询记录「不存在」的场景下,在索引树找到第一条大于该查询记录的记录后,要将该记录的索引中的 next-key lock 会退化成「间隙锁」?
原因就是在唯一索引等值查询并且查询记录不存在的场景下,仅靠间隙锁就能避免幻读的问题。
范围查询和等值查询的加锁规则是不同的。
当唯一索引进行范围查询时,会对每一个扫描到的索引加 next-key 锁,然后如果遇到下面这些情况,会退化成记录锁或者间隙锁:
接下来,通过几个实验,才验证我上面说的结论。
1、针对「大于或者大于等于」的范围查询
实验一:针对「大于」的范围查询的情况。
假设事务 A 执行了这条范围查询语句:
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where id > 15 for update; +----+-----------+-----+ | id | name | age | +----+-----------+-----+ | 20 | 香克斯 | 39 | +----+-----------+-----+ 1 row in set (0.01 sec)
事务 A 加锁变化过程如下:
可以得知,事务 A 在主键索引上加了两个 X 型 的 next-key 锁:

我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
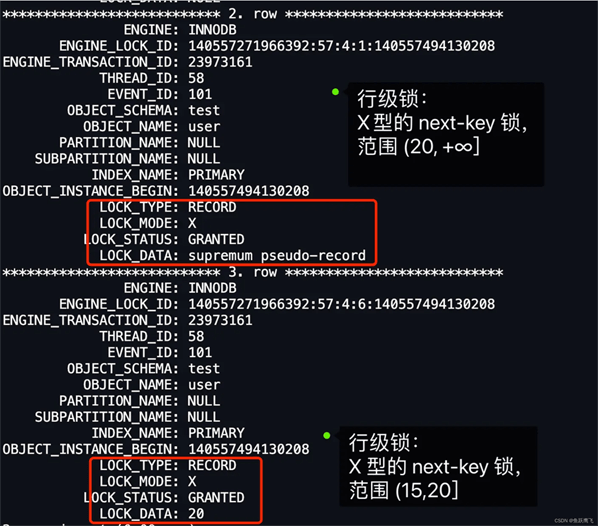
从上图中的分析中,也可以得到事务 A 在主键索引上加了两个 X 型 的next-key 锁:
实验二:针对「大于等于」的范围查询的情况。
假设事务 A 执行了这条范围查询语句:
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where id >= 15 for update; +----+-----------+-----+ | id | name | age | +----+-----------+-----+ | 15 | 乌索普 | 20 | | 20 | 香克斯 | 39 | +----+-----------+-----+ 2 rows in set (0.00 sec)
事务 A 加锁变化过程如下:
可以得知,事务 A 在主键索引上加了三个 X 型 的锁,分别是:
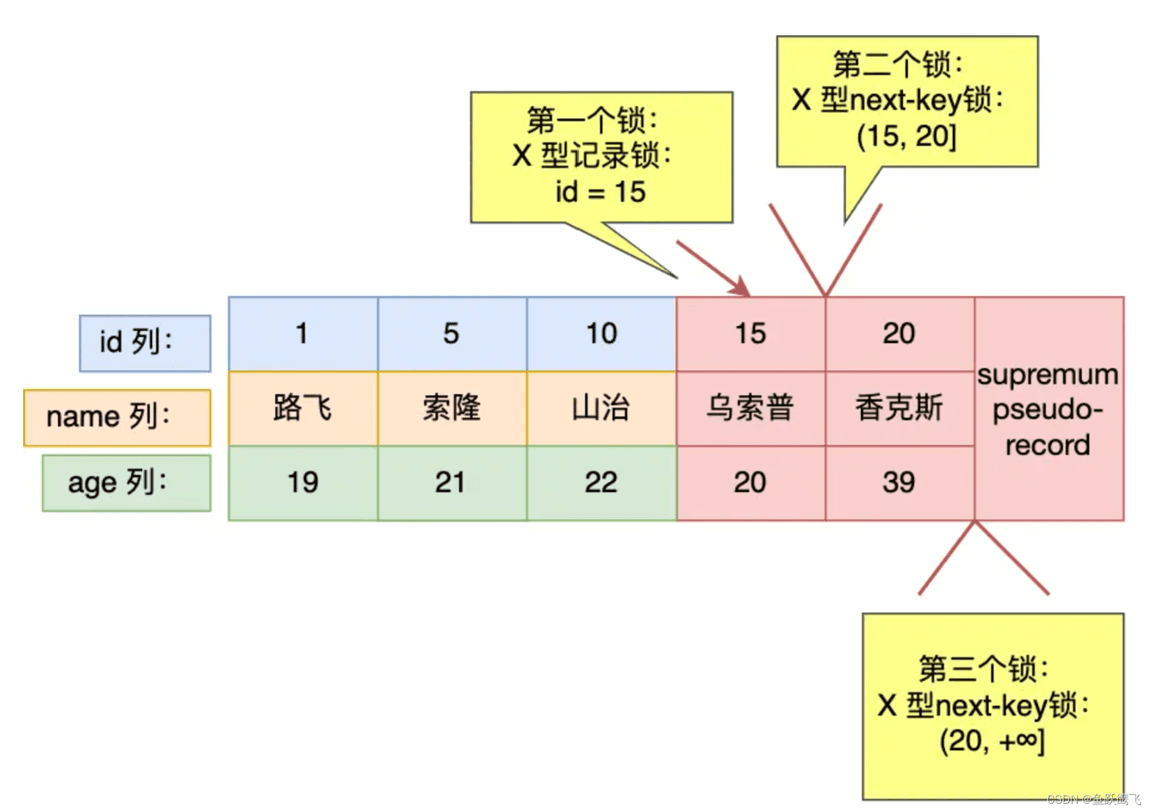
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。

通过前面这个实验,我们证明了:
2、针对「小于或者小于等于」的范围查询
实验一:针对「小于」的范围查询时,查询条件值的记录「不存在」表中的情况。
假设事务 A 执行了这条范围查询语句,注意查询条件值的记录(id 为 6)并不存在于表中。
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where id < 6 for update; +----+--------+-----+ | id | name | age | +----+--------+-----+ | 1 | 路飞 | 19 | | 5 | 索隆 | 21 | +----+--------+-----+ 3 rows in set (0.00 sec)
事务 A 加锁变化过程如下:
从上面的分析中,可以得知事务 A 在主键索引上加了三个 X 型的锁:
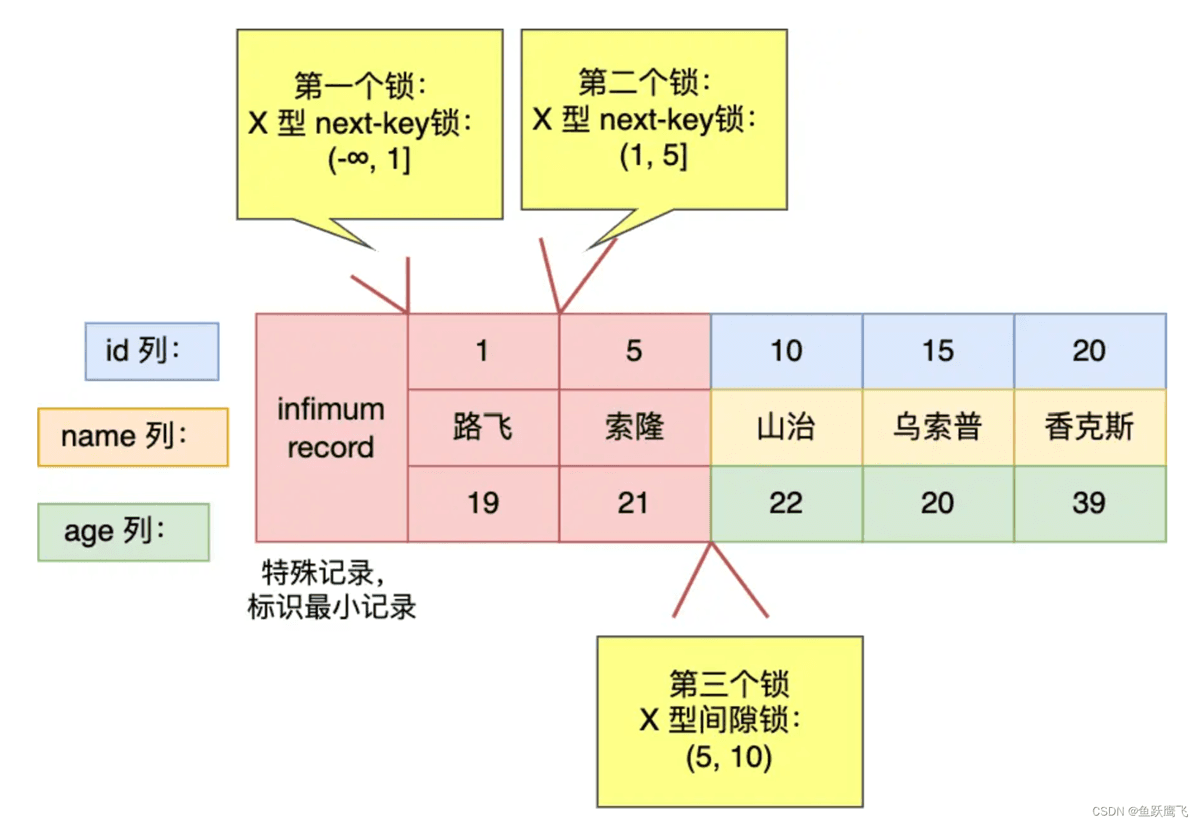
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
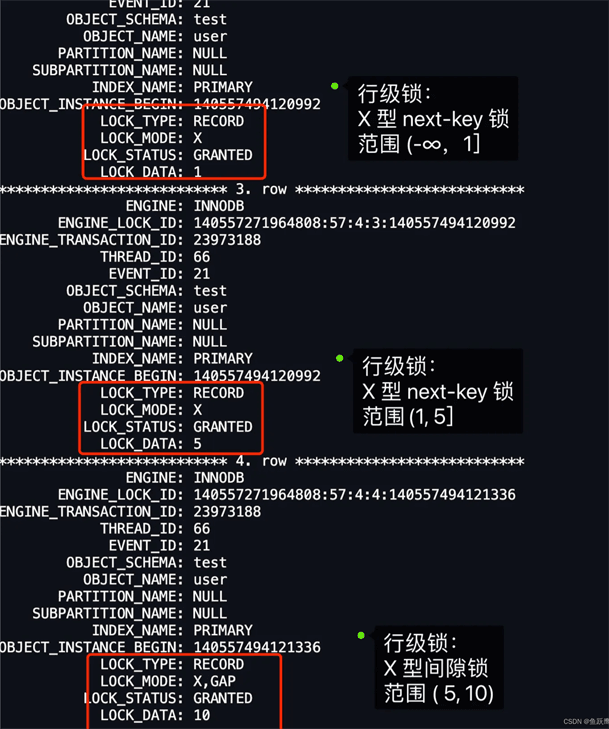
从上图中的分析中,也可以得知事务 A 在主键索引加的三个锁,就是我们前面分析出那三个锁。
虽然这次范围查询的条件是「小于」,但是查询条件值的记录不存在于表中( id 为 6 的记录不在表中),所以如果事务 A 的范围查询的条件改成 <= 6 的话,加的锁还是和范围查询条件为 < 6 是一样的。 大家自己也验证下这个结论。
因此,针对「小于或者小于等于」的唯一索引范围查询,如果条件值的记录不在表中,那么不管是「小于」还是「小于等于」的范围查询,扫描到终止范围查询的记录时,该记录中索引的 next-key 锁会退化成间隙锁,其他扫描的记录,则是在这些记录的索引上加 next-key 锁。
实验二:针对「小于等于」的范围查询时,查询条件值的记录「存在」表中的情况。
假设事务 A 执行了这条范围查询语句,注意查询条件值的记录(id 为 5)存在于表中。
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where id <= 5 for update; +----+--------+-----+ | id | name | age | +----+--------+-----+ | 1 | 路飞 | 19 | | 5 | 索隆 | 21 | +----+--------+-----+ 2 rows in set (0.00 sec)
事务 A 加锁变化过程如下:
从上面的分析中,可以得到事务 A 在主键索引上加了 2 个 X 型的锁:
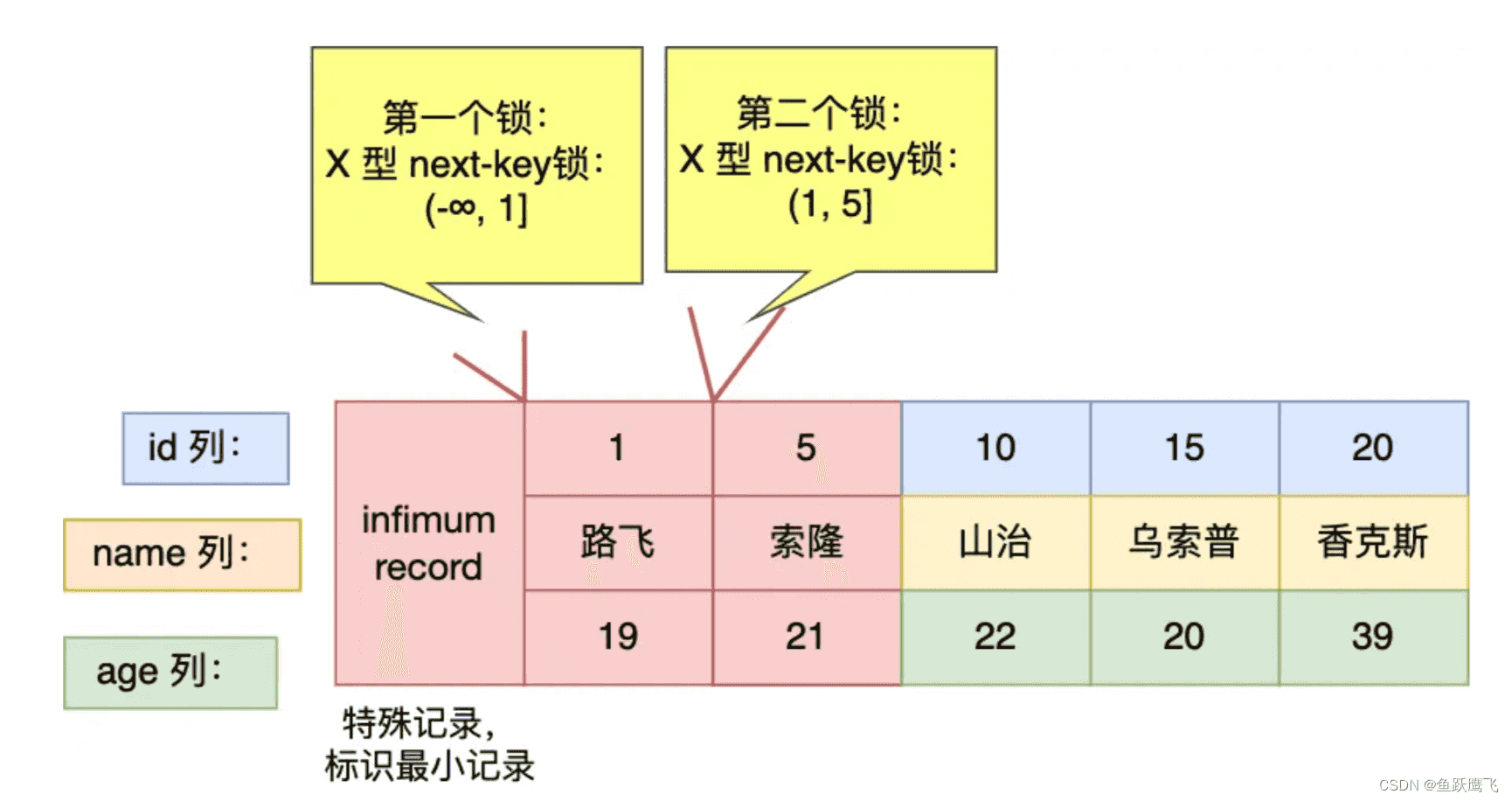
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
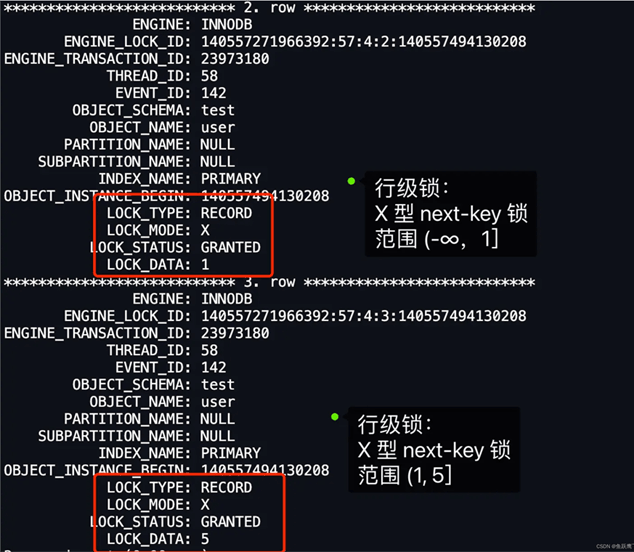
从上图中的分析中,可以得到事务 A 在主键索引上加了两个 X 型 next-key 锁,分别是:
实验三:再来看针对「小于」的范围查询时,查询条件值的记录「存在」表中的情况。
如果事务 A 的查询语句是小于的范围查询,且查询条件值的记录(id 为 5)存在于表中。
select * from user where id < 5 for update;
事务 A 加锁变化过程如下:
可以得知,此时事务 A 在主键索引上加了两种 X 型锁:
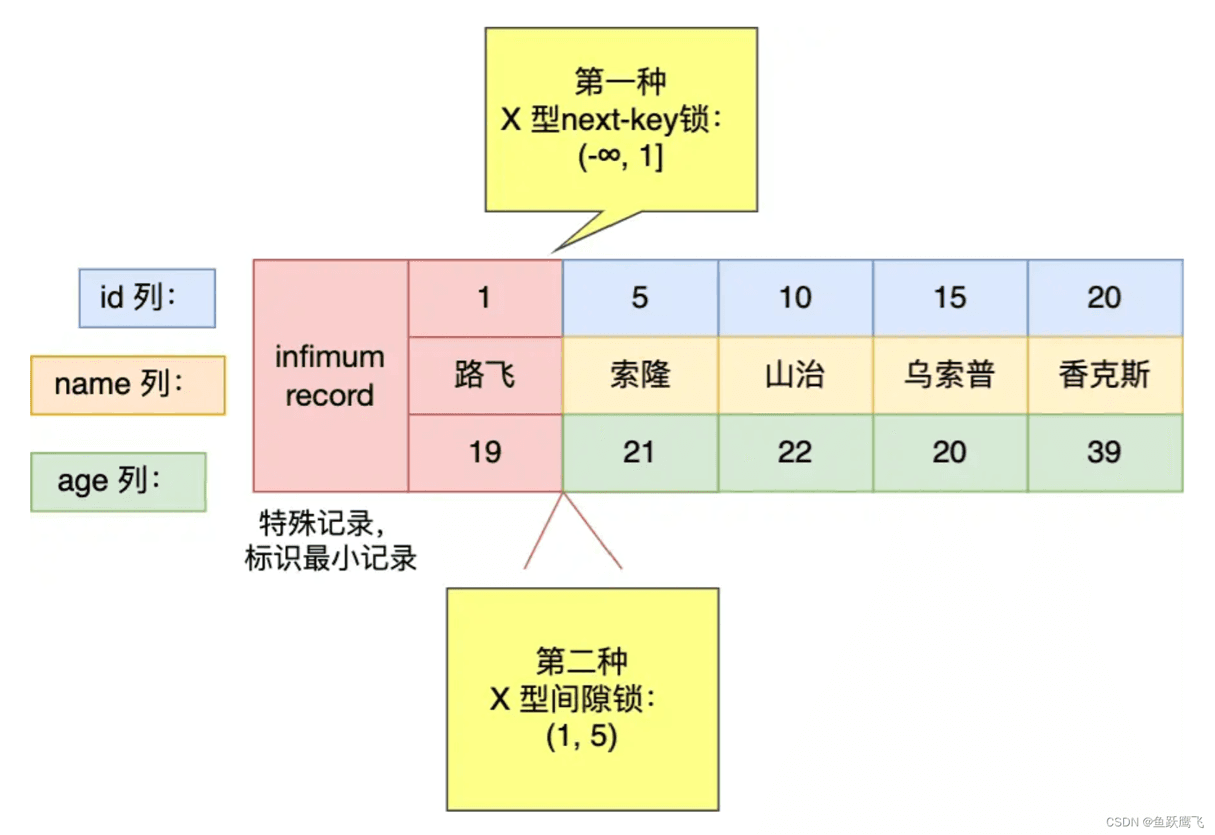
在 id = 1 这条记录的主键索引上,加了范围为 (-∞, 1] 的 next-key 锁,意味着其他事务即无法更新或者删除 id = 1 的这一条记录,同时也无法插入 id 小于 1 的这一些新记录。
在 id = 5 这条记录的主键索引上,加了范围为 (null,5) 的间隙锁,意味着其他事务无法插入 id 值为 2、3、4 的这一些新记录。
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
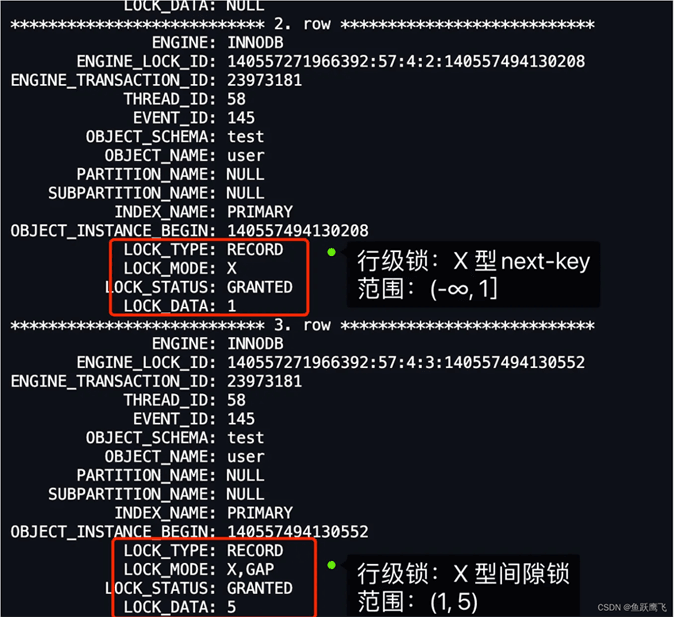
从上图中的分析中,可以得到事务 A 在主键索引上加了 X 型的范围为 (-∞, 1] 的 next-key 锁,和 X 型的范围为 (null, 5) 的间隙锁。
因此,通过前面这三个实验,可以得知。
在针对「小于或者小于等于」的唯一索引(主键索引)范围查询时,存在这两种情况会将索引的 next-key 锁会退化成间隙锁的:
当我们用非唯一索引进行等值查询的时候,因为存在两个索引,一个是主键索引,一个是非唯一索引(二级索引),所以在加锁时,同时会对这两个索引都加锁,但是对主键索引加锁的时候,只有满足查询条件的记录才会对它们的主键索引加锁。
针对非唯一索引等值查询时,查询的记录存不存在,加锁的规则也会不同:
接下里用两个实验来说明。
1、记录不存在的情况
实验一:针对非唯一索引等值查询时,查询的值不存在的情况。
先来说说非唯一索引等值查询时,查询的记录不存在的情况,因为这个比较简单。
假设事务 A 对非唯一索引(age)进行了等值查询,且表中不存在 age = 25 的记录。
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where age = 25 for update; Empty set (0.00 sec)
事务 A 加锁变化过程如下:
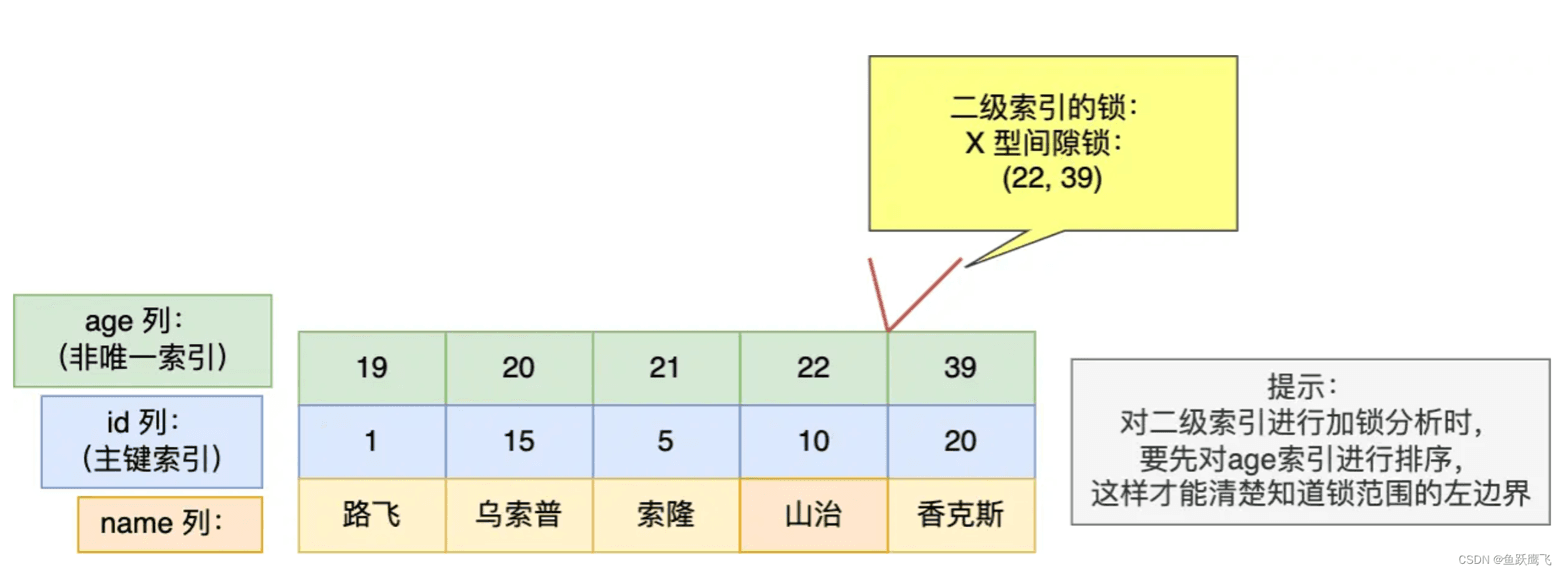
事务 A 在 age = 39 记录的二级索引上,加了 X 型的间隙锁,范围是 (null, 39)。意味着其他事务无法插入 age 值为 23、24、25、26、....、38 这些新记录。不过对于插入 age = 22 和 age = 39 记录的语句,在一些情况是可以成功插入的,而一些情况则无法成功插入,具体哪些情况,会在后面说。
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
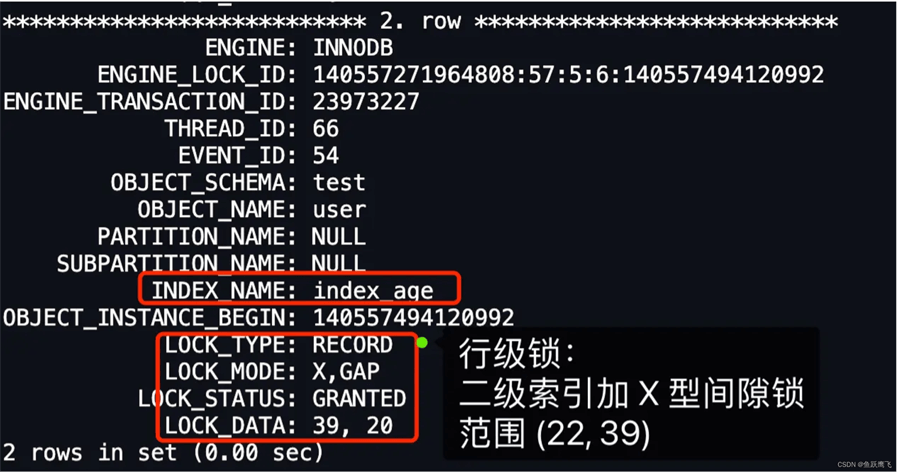
从上图的分析,可以看到,事务 A 在 age = 39 记录的二级索引上(INDEX_NAME: index_age ),加了范围为 (null, 39) 的 X 型间隙锁。
此时,如果有其他事务插入了 age 值为 23、24、25、26、....、38 这些新记录,那么这些插入语句都会发生阻塞。不过对于插入 age = 39 记录的语句,在一些情况是可以成功插入的,而一些情况则无法成功插入,具体哪些情况,接下来我们就说!
当有一个事务持有二级索引的间隙锁 (null, 39) 时,什么情况下,可以让其他事务的插入 age = 22 或者 age = 39 记录的语句成功?又是什么情况下,插入 age = 22 或者 age = 39 记录时的语句会被阻塞?
我们先要清楚,什么情况下插入语句会发生阻塞。
插入语句在插入一条记录之前,需要先定位到该记录在 B+树 的位置,如果插入的位置的下一条记录的索引上有间隙锁,才会发生阻塞。
在分析二级索引的间隙锁是否可以成功插入记录时,我们要先要知道二级索引树是如何存放记录的?
二级索引树是按照二级索引值(age列)按顺序存放的,在相同的二级索引值情况下, 再按主键 id 的顺序存放。知道了这个前提,我们才能知道执行插入语句的时候,插入的位置的下一条记录是谁。
基于前面的实验,事务 A 是在 age = 39 记录的二级索引上,加了 X 型的间隙锁,范围是 (null, 39)。
插入 age = 22 记录的成功和失败的情况分别如下:
插入 age = 39 记录的成功和失败的情况分别如下:
当其他事务插入一条 age = 39,id = 3 的记录的时候,在二级索引树上定位到插入的位置,而该位置的下一条是 id = 20、age = 39 的记录,正好该记录的二级索引上有间隙锁,所以这条插入语句会被阻塞,无法插入成功。
当其他事务插入一条 age = 39,id = 21 的记录的时候,在二级索引树上定位到插入的位置,而该位置的下一条记录不存在,也就没有间隙锁了,所以这条插入语句可以插入成功。
所以,当有一个事务持有二级索引的间隙锁 (null, 39) 时,插入 age = 22 或者 age = 39 记录的语句是否可以执行成功,关键还要考虑插入记录的主键值,因为「二级索引值(age列)+主键值(id列)」才可以确定插入的位置,确定了插入位置后,就要看插入的位置的下一条记录是否有间隙锁,如果有间隙锁,就会发生阻塞,如果没有间隙锁,则可以插入成功。
知道了这个结论之后,我们再回过头看,非唯一索引等值查询时,查询的记录不存在时,执行select * from performance_schema.data_locks\G; 输出的结果。
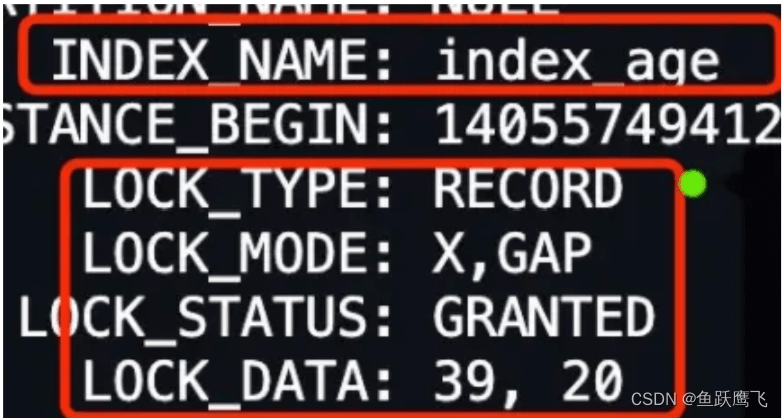
在前面分析输出结果的时候,我说的结论是:「事务 A 在 age = 39 记录的二级索引上(INDEX_NAME: index_age ),加了范围为 (null, 39) 的 X 型间隙锁」。这个结论其实还不够准确,因为只考虑了 LOCK_DATA 第一个数值(39),没有考虑 LOCK_DATA 第二个数值(20)。
那 LOCK_DATA:39,20 是什么意思?
之所以 LOCK_DATA 要多显示一个数值(ID值),是因为针对「当某个事务持有非唯一索引的 (null, 39) 间隙锁的时候,其他事务是否可以插入 age = 39 新记录」的问题,还需要考虑插入记录的 id 值。而 LOCK_DATA 的第二个数值,就是说明在插入 age = 39 新记录时,哪些范围的 id 值是不可以插入的。
因此, LOCK_DATA:39,20 + LOCK_MODE : X, GAP 的意思是,事务 A 在 age = 39 记录的二级索引上(INDEX_NAME: index_age ),加了 age 值范围为 (null, 39) 的 X 型间隙锁,**同时针对其他事务插入 age 值为 39 的新记录时,不允许插入的新记录的 id 值小于 20 **。如果插入的新记录的 id 值大于 20,则可以插入成功。
但是我们无法从select * from performance_schema.data_locks\G; 输出的结果分析出「在插入 age =22 新记录时,哪些范围的 id 值是可以插入成功的」,这时候就得自己画出二级索引的 B+ 树的结构,然后确定插入位置后,看下该位置的下一条记录是否存在间隙锁,如果存在间隙锁,则无法插入成功,如果不存在间隙锁,则可以插入成功。
2、记录存在的情况
实验二:针对非唯一索引等值查询时,查询的值存在的情况。
假设事务 A 对非唯一索引(age)进行了等值查询,且表中存在 age = 22 的记录。
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where age = 22 for update; +----+--------+-----+ | id | name | age | +----+--------+-----+ | 10 | 山治 | 22 | +----+--------+-----+ 1 row in set (0.00 sec)
事务 A 加锁变化过程如下:
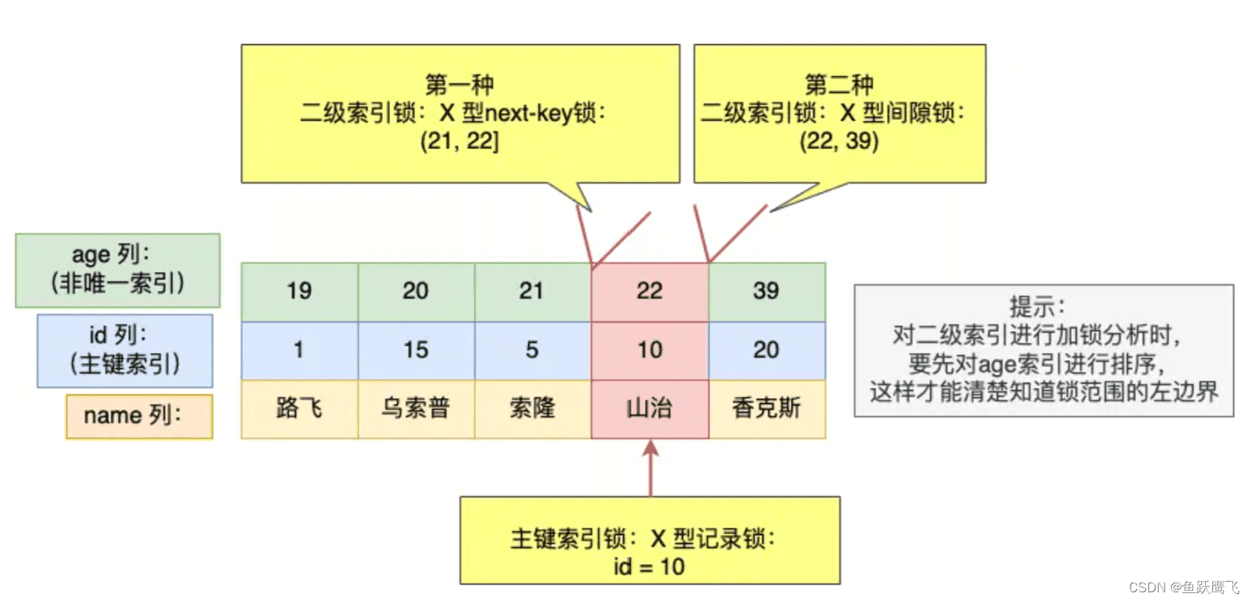
可以看到,事务 A 对主键索引和二级索引都加了 X 型的锁:
我们也可以通过 select * from performance_schema.data_locks\G; 这条语句来看看事务 A 加了什么锁。
输出结果如下,我这里只截取了行级锁的内容。
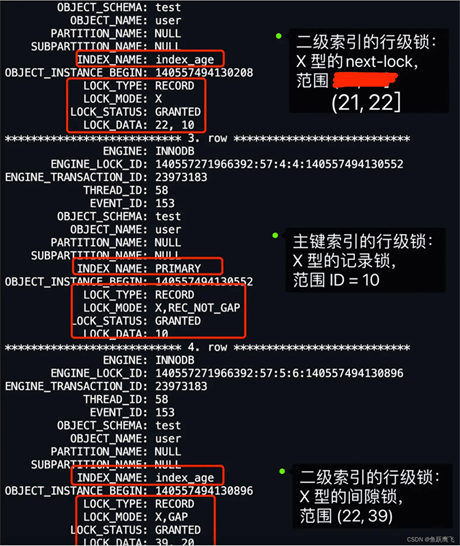
从上图的分析,可以看到,事务 A 对二级索引(INDEX_NAME: index_age )加了两个 X 型锁,分别是:
LOCK_DATA : 22, 10 可以得知,其他事务插入 age 值为 22 的新记录时,如果插入的新记录的 id 值小于 10,那么插入语句会发生阻塞;如果插入的新记录的 id 大于 10,还要看该新记录插入的位置的下一条记录是否有间隙锁,如果没有间隙锁则可以插入成功,如果有间隙锁,则无法插入成功。LOCK_DATA : 39, 20 可以得知,其他事务插入 age 值为 39 的新记录时,如果插入的新记录的 id 值小于 20,那么插入语句会发生阻塞,如果插入的新记录的 id 大于 20,则可以插入成功。同时,事务 A 还对主键索引(INDEX_NAME: PRIMARY )加了 X 型的记录锁:
为什么这个实验案例中,需要在二级索引索引上加范围 (null, 39) 的间隙锁?
要找到这个问题的答案,我们要明白 MySQL 在可重复读的隔离级别场景下,为什么要引入间隙锁?其实是为了避免幻读现象的发生。
如果这个实验案例中:
select * from user where age = 22 for update;
如果事务 A 不在二级索引索引上加范围 (null, 39) 的间隙锁,只在二级索引索引上加范围为 (null, 22] 的 next-key 锁的话,那么就会有幻读的问题。
前面我也说过,在非唯一索引上加了范围为 (null, 22] 的 next-key 锁,是无法完全锁住 age = 22 新记录的插入,因为对于是否可以插入 age = 22 的新记录,还要看插入的新记录的 id 值,从 LOCK_DATA : 22, 10 可以得知,其他事务插入 age 值为 22 的新记录时,如果插入的新记录的 id 值小于 10,那么插入语句会发生阻塞,如果插入的新记录的 id 值大于 10,则可以插入成功。
也就是说,只在二级索引索引(非唯一索引)上加范围为 (null, 22] 的 next-key 锁,其他事务是有可能插入 age 值为 22 的新记录的(比如插入一个 age = 22,id = 12 的新记录),那么如果事务 A 再一次查询 age = 22 的记录的时候,前后两次查询 age = 22 的结果集就不一样了,这时就发生了幻读的现象。
那么当在 age = 39 这条记录的二级索引索引上加了范围为 (null, 39) 的间隙锁后,其他事务是无法插入一个 age = 22,id = 12 的新记录,因为当其他事务插入一条 age = 22,id = 12 的新记录的时候,在二级索引树上定位到插入的位置,而该位置的下一条是 id = 20、age = 39 的记录,正好该记录的二级索引上有间隙锁,所以这条插入语句会被阻塞,无法插入成功,这样就避免幻读现象的发生。
所以,为了避免幻读现象的发生,就需要在二级索引索引上加范围 (null, 39) 的间隙锁。
非唯一索引和主键索引的范围查询的加锁也有所不同,不同之处在于非唯一索引范围查询,索引的 next-key lock 不会有退化为间隙锁和记录锁的情况,也就是非唯一索引进行范围查询时,对二级索引记录加锁都是加 next-key 锁。
就带大家简单分析一下,事务 A 的这条范围查询语句:
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where age >= 22 for update; +----+-----------+-----+ | id | name | age | +----+-----------+-----+ | 10 | 山治 | 22 | | 20 | 香克斯 | 39 | +----+-----------+-----+ 2 rows in set (0.01 sec)
事务 A 的加锁变化:
可以看到,事务 A 对主键索引和二级索引都加了 X 型的锁:
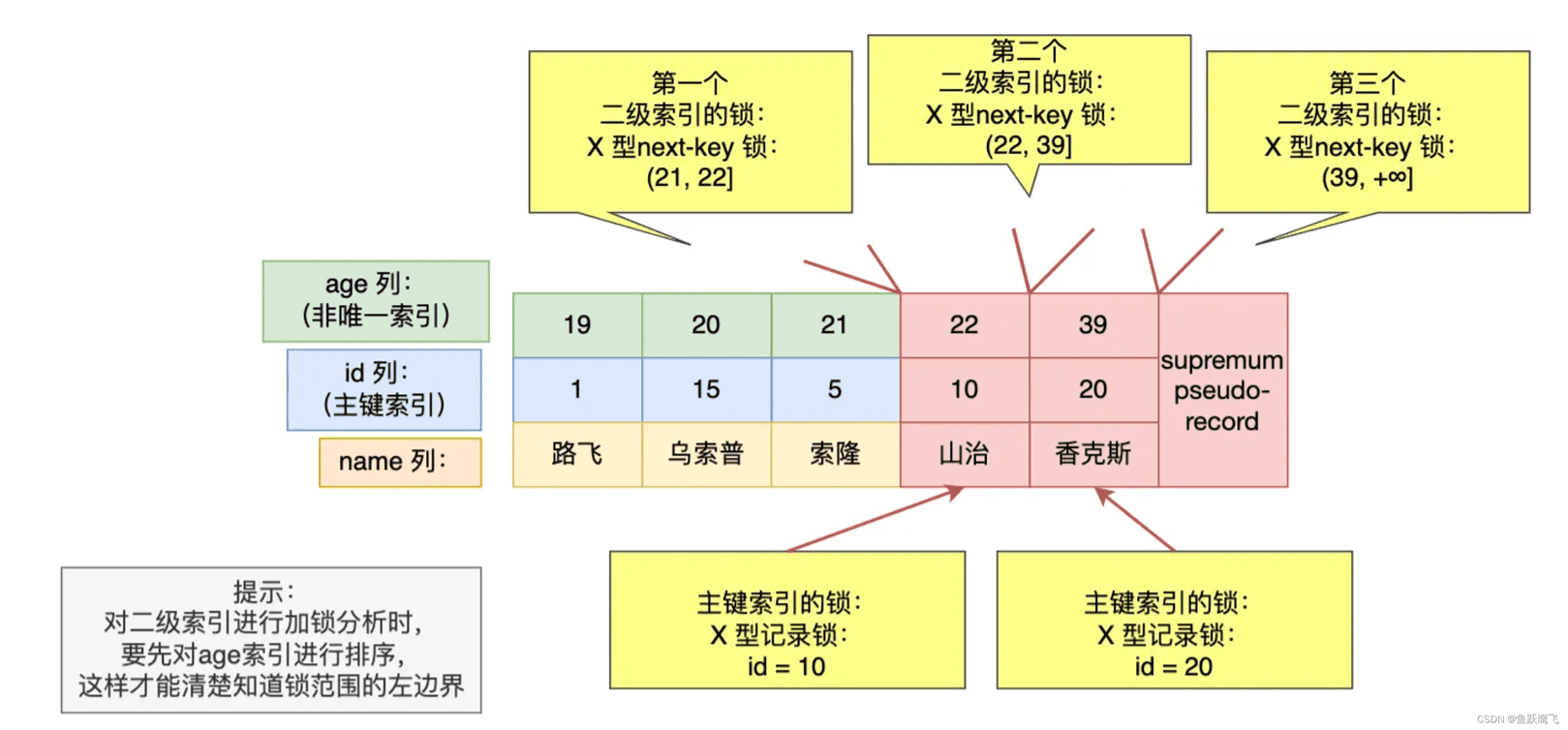
在 age >= 22 的范围查询中,明明查询 age = 22 的记录存在并且属于等值查询,为什么不会像唯一索引那样,将 age = 22 记录的二级索引上的 next-key 锁退化为记录锁?
因为 age 字段是非唯一索引,不具有唯一性,所以如果只加记录锁(记录锁无法防止插入,只能防止删除或者修改),就会导致其他事务插入一条 age = 22 的记录,这样前后两次查询的结果集就不相同了,出现了幻读现象。
前面的案例,我们的查询语句都有使用索引查询,也就是查询记录的时候,是通过索引扫描的方式查询的,然后对扫描出来的记录进行加锁。
如果锁定读查询语句,没有使用索引列作为查询条件,或者查询语句没有走索引查询,导致扫描是全表扫描。那么,每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表,这时如果其他事务对该表进行增、删、改操作的时候,都会被阻塞。
不只是锁定读查询语句不加索引才会导致这种情况,update 和 delete 语句如果查询条件不加索引,那么由于扫描的方式是全表扫描,于是就会对每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表。
因此,在线上在执行 update、delete、select ... for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
这次我以 MySQL 8.0.26 版本,在可重复读隔离级别之下,做了几个实验,让大家了解了唯一索引和非唯一索引的行级锁的加锁规则。
我这里总结下, MySQL 行级锁的加锁规则。
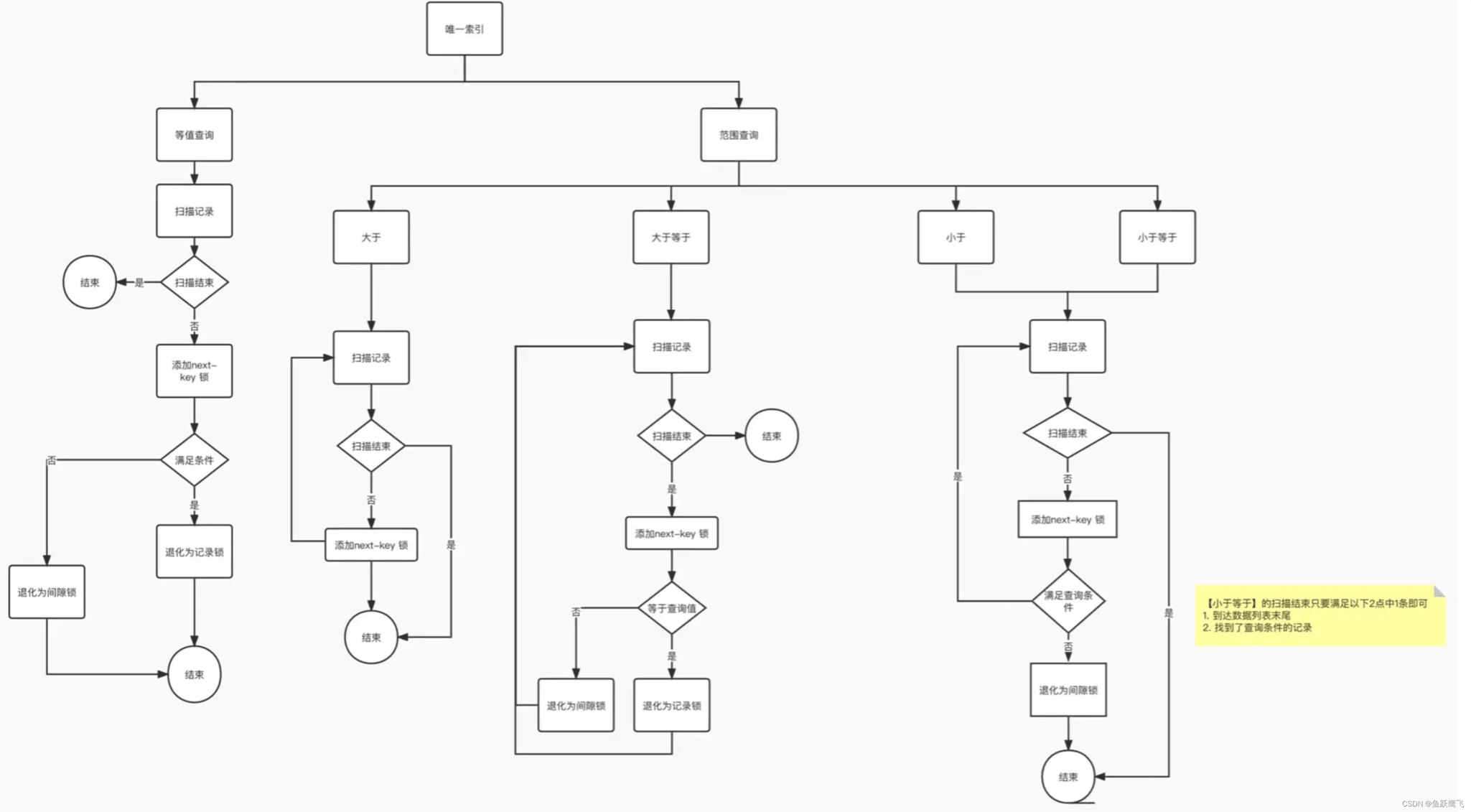
唯一索引等值查询:
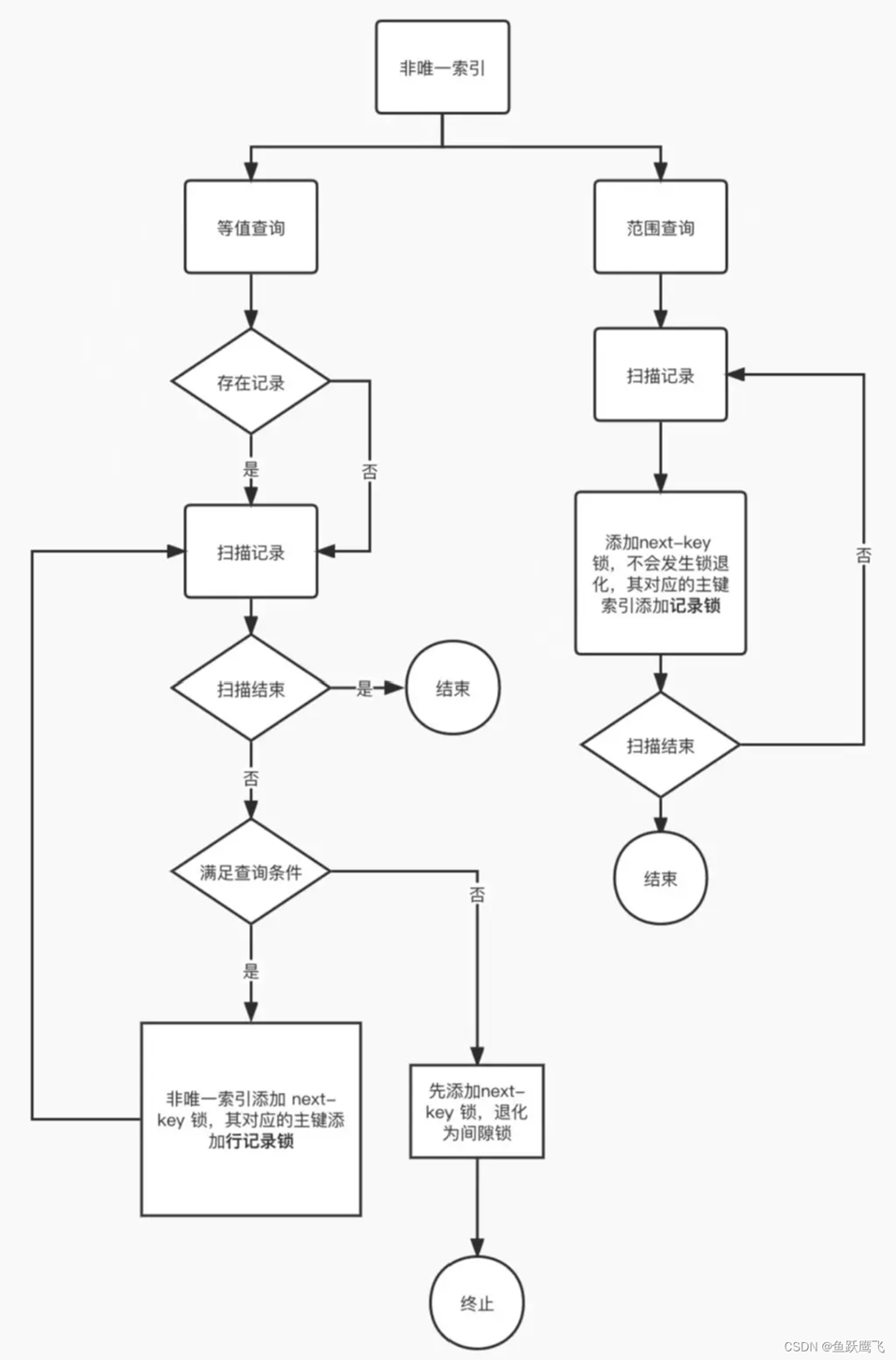
非唯一索引等值查询:
非唯一索引和主键索引的范围查询的加锁规则不同之处在于:
其实理解 MySQL 为什么要这样加锁,主要要以避免幻读角度去分析,这样就很容易理解这些加锁的规则了。
还有一件很重要的事情,在线上在执行 update、delete、select ... for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
唯一索引(主键索引)加锁的流程图如下。(注意这个流程图是针对「主键索引」的,如果是二级索引的唯一索引,除了流程图中对二级索引的加锁规则之外,还会对查询到的记录的主键索引项加「记录锁」,流程图没有提示这一个点,所以在这里用文字补充说明下)
非唯一索引加锁的流程图:
到此这篇关于深入理解MySQL中的行级锁的文章就介绍到这了,更多相关MySQL 行级锁内容请搜索插件窝以前的文章或继续浏览下面的相关文章希望大家以后多多支持插件窝!