Dropout是一种在神经网络训练过程中用于防止过拟合的技术。在训练过程中,Dropout会随机地关闭一部分神经元,这样可以使模型更加健壮,不会过度依赖于任何一个特定的神经元,从而提高模型的泛化能力。下面是一些使用技巧:
技巧1:在输入层和隐藏层上使用Dropout。这个技巧是基于Dropout的两个作用,即增加网络的多样性和增加数据的多样性。在输入层上使用Dropout,相当于对数据进行噪声注入,可以提高数据的鲁棒性,防止网络对数据的细节过度敏感。在隐藏层上使用Dropout,相当于对网络进行子采样,可以提高网络的泛化能力,防止网络对特定的特征过度依赖。在网络的每一层都使用Dropout,可以进一步增强这两个作用,但也要注意不要过度使用,导致网络的训练不充分。
技巧2:网络中的Dropout率为0.2~0.5。这个技巧是基于经验的建议,一般来说,Dropout率太低会导致Dropout的效果不明显,Dropout率太高会导致网络的训练不充分。不过,这个技巧也不是绝对的,有些研究发现,Dropout率可以超过0.5,甚至接近1,仍然可以取得很好的效果。这可能取决于网络的复杂度,数据的规模,以及其他的正则化方法。
技巧3:在较大的网络上使用Dropout。这个技巧是基于Dropout的本质,即通过随机地删除网络中的一些连接,来防止网络的过拟合。在较大的网络上,过拟合的风险更高,因此Dropout的作用更明显。不过,这并不意味着在较小的网络上使用Dropout就没有意义,只是效果可能不如在较大的网络上显著。
技巧4:使用较高的学习率,使用学习率衰减和设置较大的动量值。这个技巧是基于Dropout的另一个作用,即增加网络的稳定性。由于Dropout会随机地改变网络的结构,导致网络的输出有较大的方差,因此需要使用较高的学习率,来加快网络的收敛速度。同时,使用学习率衰减,可以在网络接近最优解时,减小学习率,避免网络的震荡。另外,使用较大的动量值,可以增加网络的惯性,抵抗Dropout带来的扰动,保持网络的方向。这个技巧的具体参数,需要根据网络的结构和数据的特点进行调节。
技巧5:限制网络权重的大小,使用最大范数正则化。这个技巧是基于Dropout的一个局限,即Dropout不能完全防止网络的过拟合。尤其是使用较高的学习率时,网络的权重可能会变得非常大,导致网络的输出过于敏感,降低网络的泛化能力。因此,需要对网络的权重进行约束,限制其大小,防止网络的过拟合。最大范数正则化是一种常用的方法,它可以限制网络的权重的范数不超过一个给定的阈值,从而控制网络的复杂度。
下面是一个例子:
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer1 = nn.Linear(null, 20)
self.layer2 = nn.Linear(null, 20)
self.layer3 = nn.Linear(null, 4)
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
x = F.relu(self.layer1(x))
x = self.dropout(x)
x = F.relu(self.layer2(x))
x = self.dropout(x)
return self.layer3(x)核心思想:R-Dropout的核心思想是在训练过程中通过正则化手段减少模型在同一输入数据上两次前向传播(每次都应用Dropout)结果之间的差异。这种方法强制模型在面对输入数据的不同“视角”(即,不同的Dropout掩码)时,学习到更一致的表示。通过这种方式,R-Dropout鼓励模型捕获更稳健的特征,从而提高模型的泛化能力。
实现方式:实现R-Dropout时,通常会对同一批数据进行两次独立的前向传播,每次前向传播都应用不同的Dropout模式。然后,通过比较这两次前向传播的结果(例如,使用KL散度作为两个分布之间差异的度量),将这种差异作为额外的正则化损失添加到总损失中。
下面是一个简单的例子,展示了如何在一个简单的全连接神经网络中实现R-Dropout。
使用KL散度作为前两次前向传播结果之间差异的度量,并将其添加到原始损失中。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class RDropoutNN(nn.Module):
def __init__(self):
super(RDropoutNN, self).__init__()
self.fc1 = nn.Linear(null, 256)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(null, 10)
def forward(self, x, with_dropout=True):
x = F.relu(self.fc1(x))
if with_dropout:
x = self.dropout(x)
x = self.fc2(x)
return x
def compute_kl_loss(p, q):
p_log_q = F.kl_div(F.log_softmax(p, dim=1), F.softmax(q, dim=1), reduction='sum')
q_log_p = F.kl_div(F.log_softmax(q, dim=1), F.softmax(p, dim=1), reduction='sum')
return (p_log_q + q_log_p) / 2
# 假设
model = RDropoutNN()
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 假设有一个数据加载器
# for inputs, labels in data_loader:
# 模拟数据
inputs = torch.randn(null, 784) # 假设的输入
labels = torch.randint(null, 10, (null,)) # 假设的标签
# 清零梯度
optimizer.zero_grad()
# 两次前向传播,每次都使用Dropout
outputs1 = model(inputs, with_dropout=True)
outputs2 = model(inputs, with_dropout=True)
# 计算原始损失
loss1 = criterion(outputs1, labels)
loss2 = criterion(outputs2, labels)
original_loss = (loss1 + loss2) / 2
# 计算R-Dropout正则化项
kl_loss = compute_kl_loss(outputs1, outputs2)
# 最终损失
lambda_kl = 0.5 # R-Dropout正则化项的权重
total_loss = original_loss + lambda_kl * kl_loss
# 反向传播和优化
total_loss.backward()
optimizer.step()在这个例子中,对相同的输入执行两次前向传播,每次都应用Dropout。然后,分别计算这两个输出对应的交叉熵损失,并将它们的平均值作为原始损失。接着,使用KL散度计算两次输出之间的差异作为R-Dropout的正则化项,并将其加到原始损失中以得到最终的损失。最后,通过反向传播更新模型的权重。
通过引入R-Dropout正则化项,鼓励模型生成更一致的输出,即使在应用不同的Dropout掩码时也是如此。这有助于提高模型的泛化能力,并进一步减少过拟合的风险。
核心思想:Multi-Sample Dropout的核心思想是在单次前向传播过程中对同一输入应用多次Dropout,产生多个不同的掩码,并对结果进行聚合(例如,通过取平均化)。这种方法的目的是在每次训练迭代中更充分地利用Dropout,以实现更快的收敛和更好的泛化。
实现方式:在实现Multi-Sample Dropout时,会在模型的关键层中并行引入多个Dropout层,每个Dropout层对输入数据应用不同的随机掩码。然后,将这些Dropout层的输出以某种方式(通常是平均)合并,以产生最终的输出。这种方法运行模型在每次迭代中考虑多种“丢弃模式”,从而增加了训练的鲁棒性。
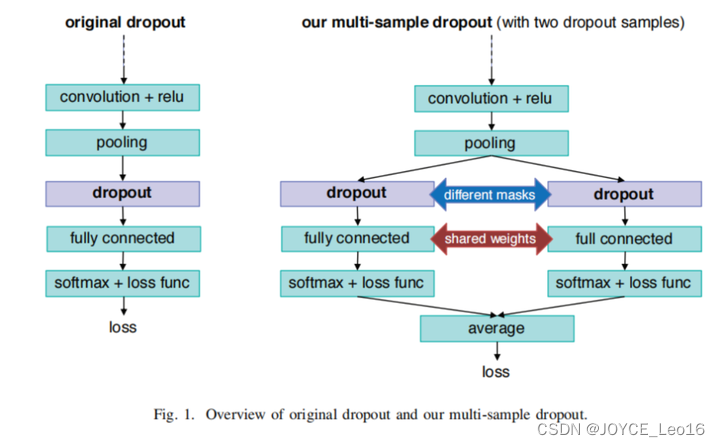
以下是一个使用Multi-Sample Dropout的例子:
class MultiSampleDropout(nn.Module):
def __init__(self, dropout_rate, num_samples):
super(MultiSampleDropout, self).__init__()
self.dropout_rate = dropout_rate
self.num_samples = num_samples
def forward(self, x):
outputs = []
for _ in range(self.num_samples):
output = F.dropout(x, self.dropout_rate, training=self.training)
outputs.append(output)
return torch.mean(torch.stack(outputs), dim=0)在每次前向传播过程中对输入进行多次采样,然后将这些采样的结果合并,从而得到最终的输出。
以上两种拓展的区别:
Dropout通过随机将神经元的激活输出置为零来工作,而DropConnect则是随机将网络的权重置为零。这意味着在DropConnect中,网络的连接(即权重)部分被随机“丢弃”,而不是输出。这种方法可以视为Dropout的一种泛化形式,并且理论上可以提供更强的正则化效果,因为它直接操作模型的权重。
DropConnect的工作原理:在每次训练迭代中,DropConnect随机选择一部分权重,并将这些权重暂时设置为0。这个过程减少了模型的容量,迫使网络在缺少一部分连接的情况下学习,从而有助于防止过拟合。与Dropout不同,DropoutConnect不是丢弃神经元的输出,而是直接在网络的权重上施加约束。
DropConnect的实现:在PyTorch中实现DropConnect相对简单,但需要自定义网络层,因为PyTorch的标准层不直接支持这种操作。下面是一个简单的示例,展示了如何实现一个具有DropConnect功能的全连接层:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DropConnect(nn.Module):
def __init__(self, input_dim, output_dim, drop_prob=0.5):
super(DropConnect, self).__init__()
self.drop_prob = drop_prob
self.weight = nn.Parameter(torch.randn(input_dim, output_dim))
self.bias = nn.Parameter(torch.randn(output_dim))
def forward(self, x):
if self.training:
# 生成与权重相同形状的掩码
mask = torch.rand(self.weight.size()) > self.drop_prob
# 应用DropConnect:用掩码乘以权重
drop_weight = self.weight * mask.float().to(self.weight.device)
else:
# 在测试时不应用DropConnect,但要调整权重以反映丢弃率
drop_weight = self.weight * (1 - self.drop_prob)
return F.linear(x, drop_weight, self.bias)
# 使用DropConnect层的示例网络
class ExampleNet(nn.Module):
def __init__(self):
super(ExampleNet, self).__init__()
self.dropconnect_layer = DropConnect(null, 10, drop_prob=0.5)
self.fc2 = nn.Linear(null, 2)
def forward(self, x):
x = F.relu(self.dropconnect_layer(x))
x = self.fc2(x)
return x
# 示例使用
model = ExampleNet()
input = torch.randn(null, 20) # 假设的输入
output = model(input)
print(output)在这个例子中,DropConnect类定义了一个自定义的全连接层,其中包含了DropConnect功能。在每次前向传播时,如果模型处于训练模式,它会随机生成一个与权重相同形状的掩码,并用这个掩码乘以权重,从而实现DropConnect效果。在评估模式下,为了保持输出的期望值不变,权重会被调整,以反映在训练时的平均丢弃率。
这种自定义层可以被嵌入到更复杂的网络结构中,以提供DropConnect正则化的效果,从而帮助减少过拟合并提高模型的泛化能力。
Standout是一种自适应的正则化方法,类似于Dropout和DropConnect,但它通过依赖于网络的激活来动态调整每个神经元被丢弃的概率。
这种方法的核心思想是利用神经网络内部的状态来决定哪些神经元更可能被保留,从而使正则化过程更加依赖于模型当前的行为。
这种自适应性使Standout能够在不同的训练阶段和不同的数据点上实现个性化的正则化强度。
Standout的工作原理:Standout通过一个额外的网络或层来计算每个神经元的保留概率。这个保留概率不是固定不变的,而是根据网络当前的激活动态调整的。具体来说,对于每个神经元,其保留概率是其激活的函数,这意味着网络在训练过程中自动学习每个神经元的重要性,并据此调整其被丢弃的概率。
Standout是数学表达式如下:
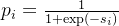
其中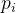 是第
是第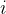 个神经元被丢弃的概率,是一个仿射函数,可以表示为:
个神经元被丢弃的概率,是一个仿射函数,可以表示为:
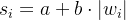
其中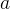 和
和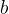 是超参数,
是超参数,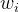 是第个神经元的权重。可以看出,权重越大,丢弃概率越大。
是第个神经元的权重。可以看出,权重越大,丢弃概率越大。
Standout的PyTorch实现:在PyTorch中实现Standout需要自定义一个层,这个层能够根据输入激活动态计算每个神经元的丢弃概率。
以下是一个简化的示例,说明如何实现这样的层:
import torch
import torch.nn as nn
class Standout(nn.Module):
def __init__(self, input_dim, output_dim):
super(Standout, self).__init__()
self.fc = nn.Linear(input_dim, output_dim)
# 使用一个简单的全连接层来生成保留概率
self.prob_fc = nn.Linear(input_dim, output_dim)
def forward(self, x):
# 计算正常的前向传播
x_out = self.fc(x)
if self.training:
# 计算每个神经元的保留概率
probs = torch.sigmoid(self.prob_fc(x))
# 生成与激活大小相同的二值掩码
mask = torch.bernoulli(probs).to(x.device)
# 应用mask
x_out = x_out * mask
# 注意:在评估模式下不应用Standout
return x_out在这个实现中,self.prob_fc 层输出的是每个神经元的保留概率,而不是丢弃概率,这些概率通过Sigmoid 函数进行了归一化。接着,使用这些概率生成一个二值掩码,该掩码通过伯努利采样得到,最后将这个掩码应用到 self.fc 层的输出上,以实现神经元的随机保留。
需要注意的是,由于Standout的自适应性,它的行为会比传统的Dropout或DropConnect更复杂,可能需要更细致的调参和监控以确保训练稳定性和模型性能。
Gaussian Dropout 是一种正则化技术,它在训练神经网络时通过引入服从高斯分布的随机噪声来防止过拟合。
不同于传统 Dropout 以固定概率将激活置零,Gaussian Dropout 乘以一个随机变量 ( m ),其中 ( m ) 服从高斯分布 ( N(null, \sigma^2) )。
PyTorch 示例:
import torch
import torch.nn as nn
class GaussianDropout(nn.Module):
def __init__(self, sigma=0.1):
super(GaussianDropout, self).__init__()
self.sigma = sigma
def forward(self, x):
if self.training:
# 生成服从高斯分布 N(null, sigma^2) 的随机变量
gaussian_noise = torch.normal(1.0, self.sigma, size=x.size()).to(x.device)
# 应用高斯 dropout
return x * gaussian_noise
else:
# 测试阶段不使用 dropout
return x
# 使用示例
layer = GaussianDropout(sigma=0.1)
input_tensor = torch.randn(null, 20) # 假设的输入
output = layer(input_tensor)在训练阶段,forward 方法生成高斯噪声并应用于输入 x,而在测试阶段直接返回 x,不应用噪声。
以上为个人经验,希望对您有所帮助。