对于车牌而言,选用的正则表达式是"^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼A-Z]{1}[A-Z]{1}\s{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$",使用re模块中的findall方法可以对输入的车牌进行合法性判定
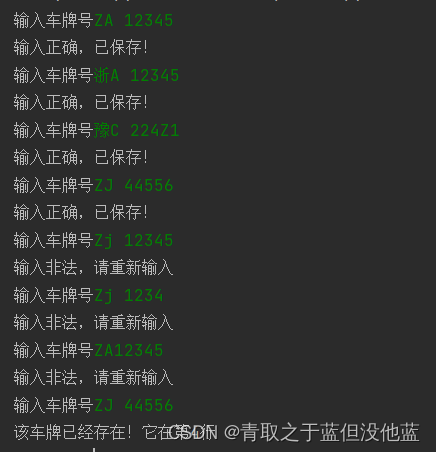
可以看到输入的车牌号可以为汉字也可以是全英文,对车牌号数字数量不够或车牌号输入错误都会判定为输入非法,而正确的非重复的会将其保存至文本文件里,正确的重复的将不会保存。

import re
paizi=[]
pattern_str = "^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼A-Z]{1}[A-Z]{1}\s{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$"
def is_car_number(pattern, string):
if re.findall(pattern, string):
return 1
else:
return 2
if __name__ == '__main__':
while True:
string_str=input('输入车牌号')
fp_exercise4 = open(r'D:\浙理课程相关资料\2022-2023上\python\exercise4_test.txt', 'a+')
if is_car_number(pattern_str, string_str)==2:
print("输入非法,请重新输入")
else:
paizi.append(string_str)#加到列表中,用于判定重复
if paizi.count(string_str)==2:#检测到重复信号
print("该车牌已经存在!它在第{}行".format(paizi.index(string_str)+1))
else:
print("输入正确,已保存!")
fp_exercise4.write(string_str + '\n')
fp_exercise4.close()新能源
组成:省份简称(1位汉字)+发牌机关代号(1位字母)+序号(6位),总计8个字符,序号不能出现字母I和字母O
* 通用规则:不区分大小写,第一位:省份简称(1位汉字),第二位:发牌机关代号(1位字母)
* 序号位:
* 小型车,第一位:只能用字母D或字母F,第二位:字母或者数字,后四位:必须使用数字
* ---([DF][A-HJ-NP-Z0-9][0-9]{4})
* 大型车,前五位:必须使用数字,第六位:只能用字母D或字母F。
* ----([0-9]{5}[DF])
/^([京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[a-zA-Z](([DF]((?![IO])[a-zA-Z0-9](?![IO]))[0-9]{4})|([0-9]{5}[DF]))|[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1})$/
到此这篇关于python正则表达式完成车牌号检验的文章就介绍到这了,更多相关python正则检验车牌号内容请搜索插件窝以前的文章或继续浏览下面的相关文章希望大家以后多多支持插件窝!