最开始,博主介绍一下自己的环境:SQL Sever 2008 R2
SQL Sever 大致都差不多
首先找到下载SQL Sever中提供的导入导出工具

如果开始界面没有找到自己下载的路径
C:\Program Files\Microsoft SQL Server\100\DTS\Binn下的DTSWizard.exe文件


这里博主导出到Excel文件当中
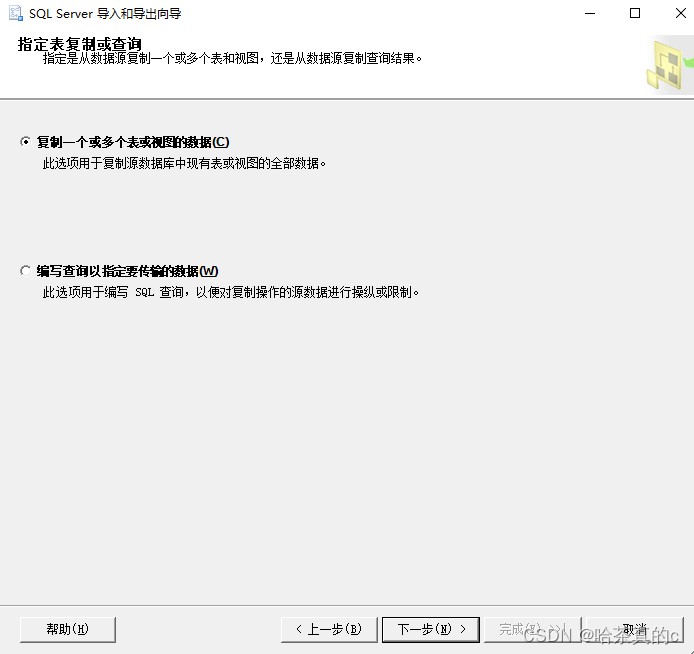
查询的话将自己在SSMS上编写的SQL语句直接复制到框中即可(确保SQL正确,可以进行测试!)
这里博主直接导出表中数据
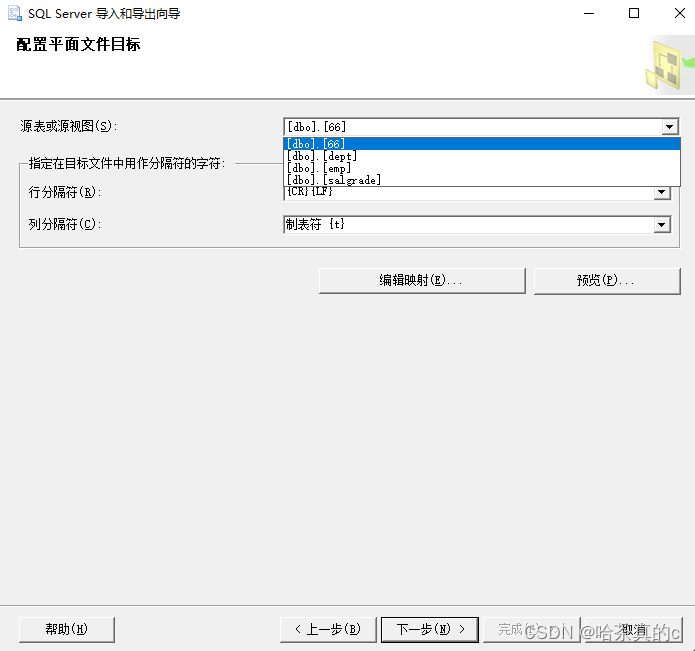
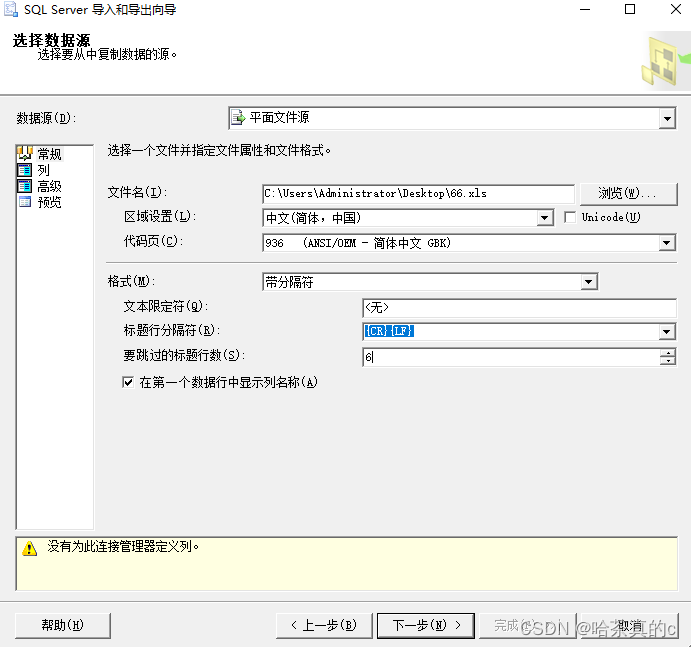
这里需要切记表的分隔符为:
行:{CR}{LF}
列:制表符
格式不对,可能导出的结构出错
(也就是不按照行列的方式导入到Excel当中!)
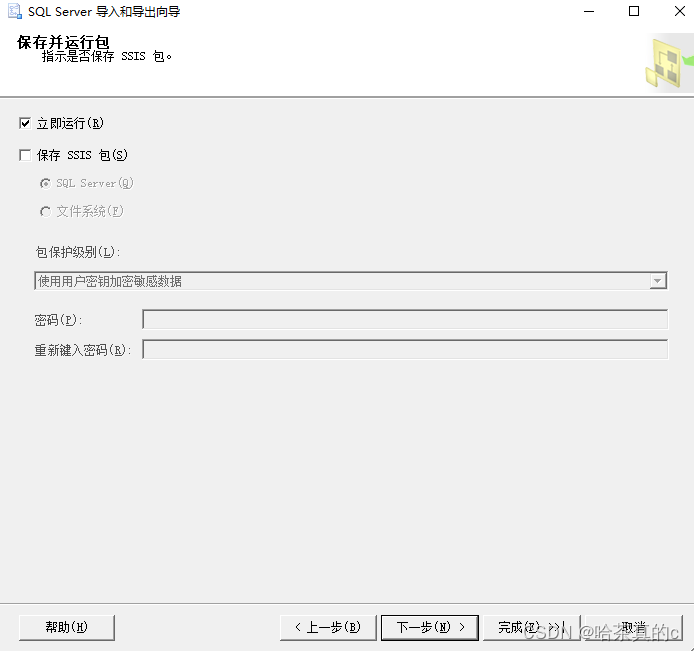
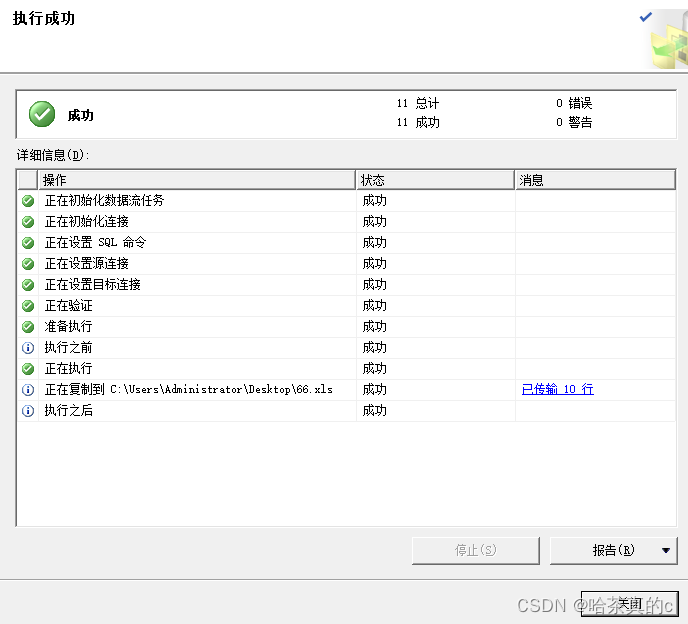
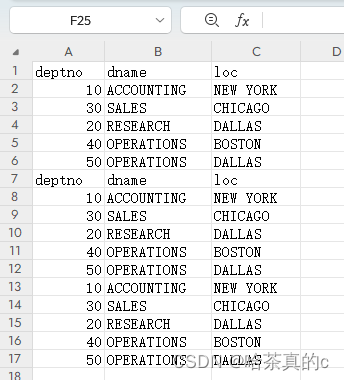
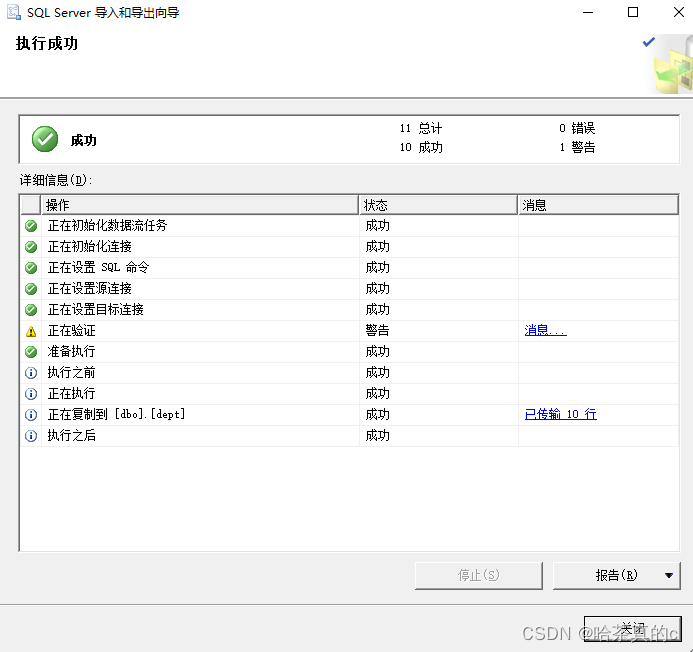
可以看到Excel表格中出现新数据!
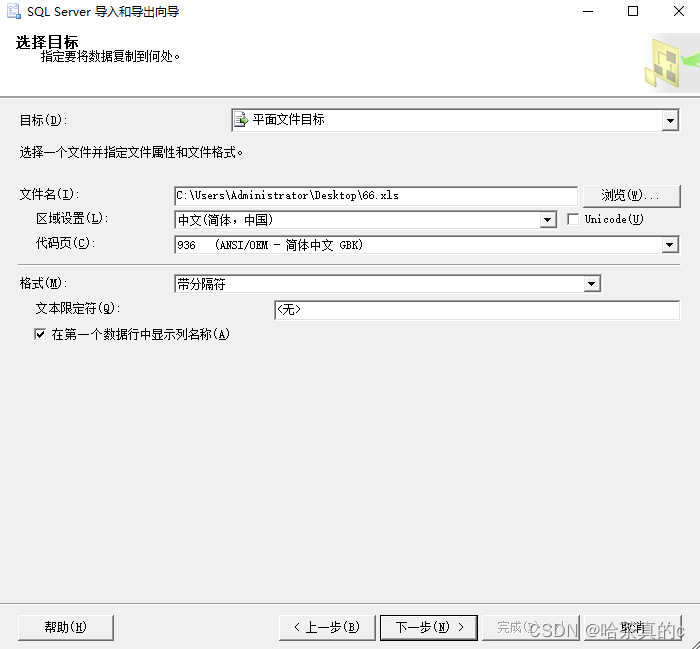
这里博主选择的是Excel表格
这里的标题分隔符选{CR}{LF}
这里博主前面有6行垃圾数据(所以选择跳过6行)
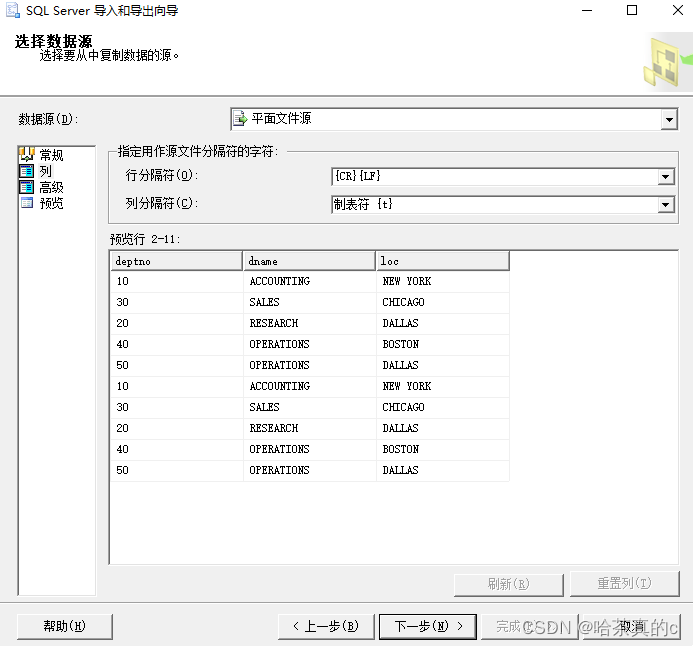
行分隔符{CR}{LF}
列分隔符制表符
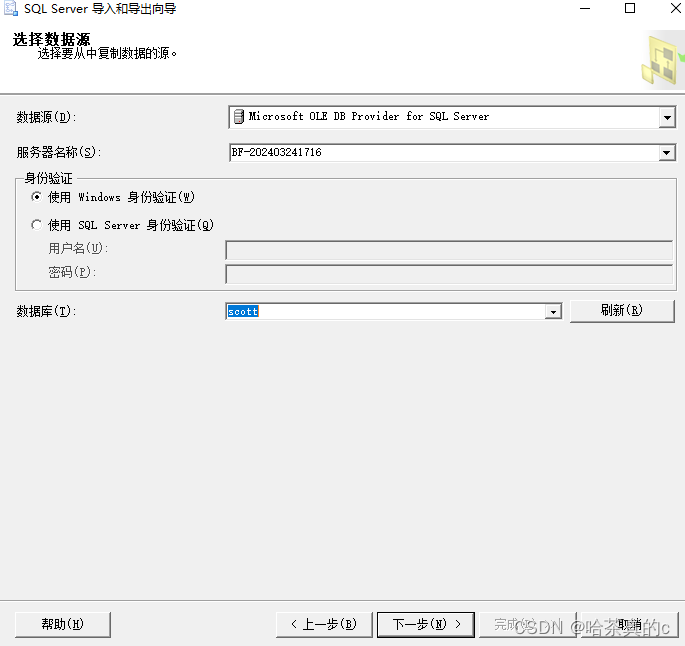
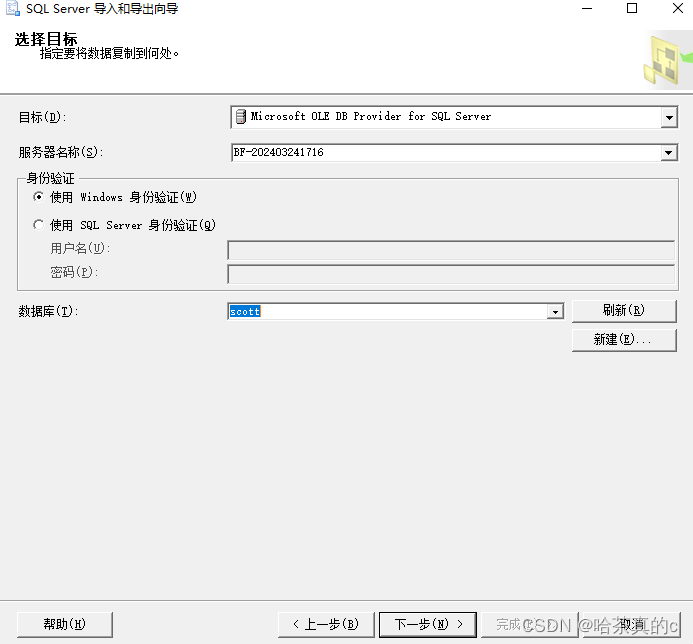
选择自己的服务器和数据库
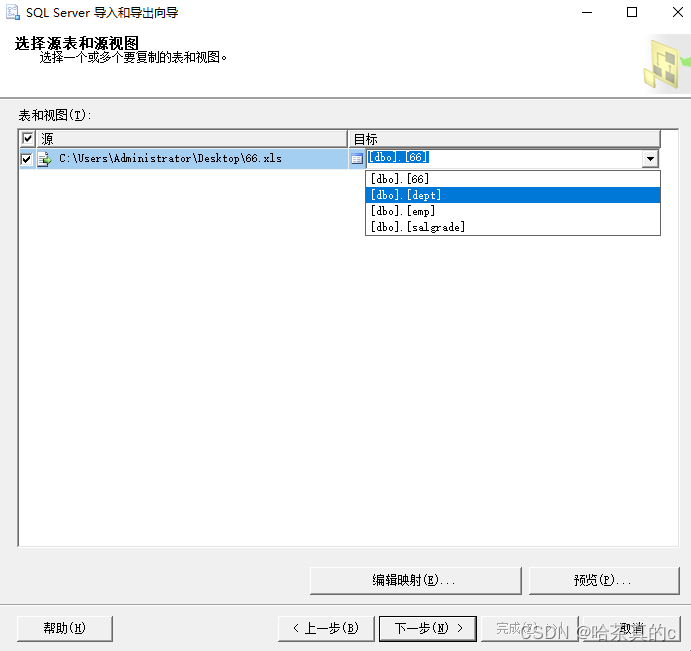
导入的目标表
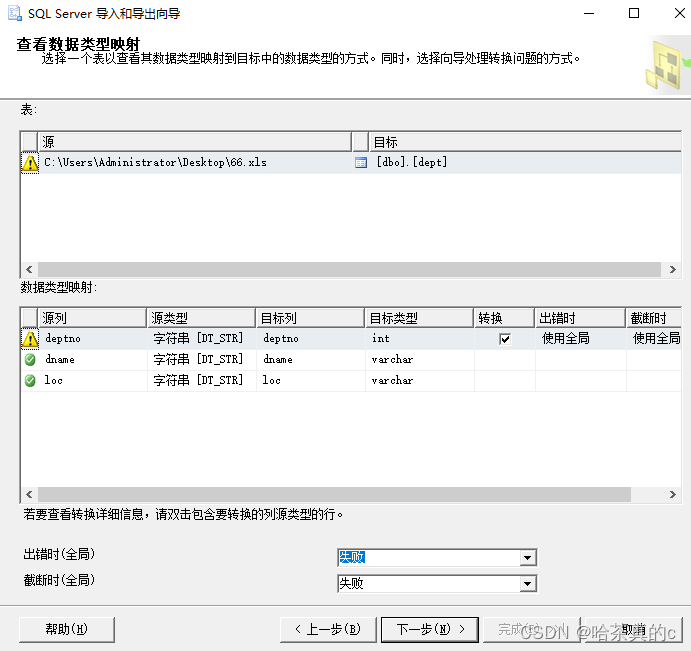
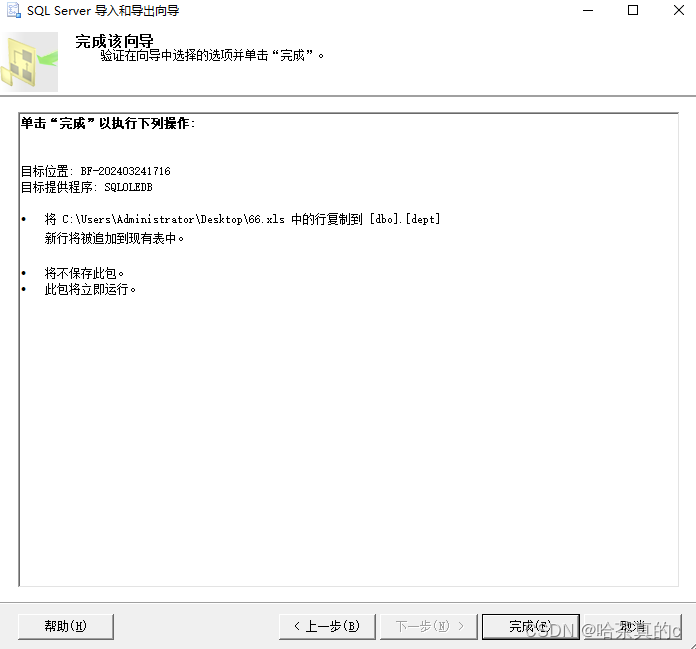
选择SSMS工具
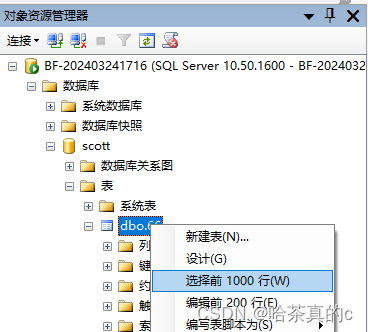
打开对应的表和数据行
查看数据,可以看到数据导入成功!
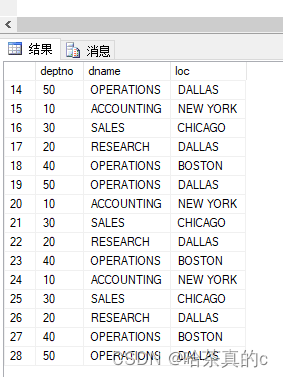
这是SQLSever2008R2所独有的,其他版本不清楚,自行了解!
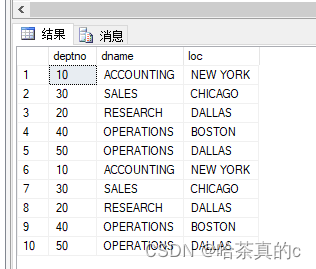
对于还未和SQL Sever数据库建立过链接的新建Excel表格无法导入导出数据!
所以咱们需要先让Excel表格和数据库建立连接

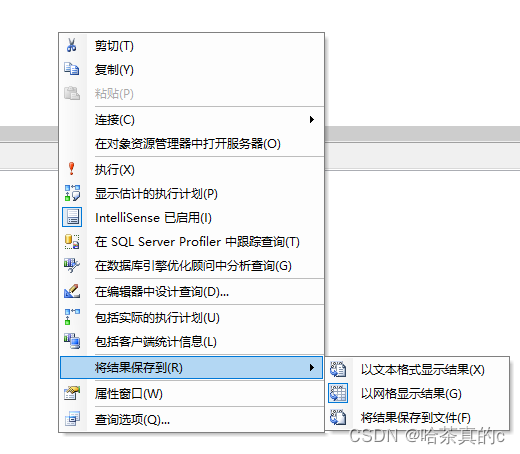
右键SQL语句框出现如下界面
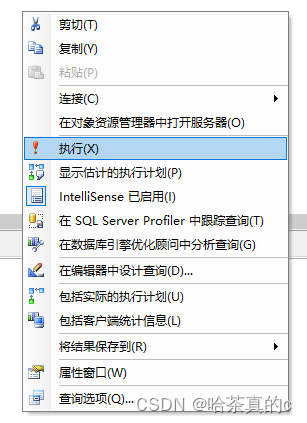
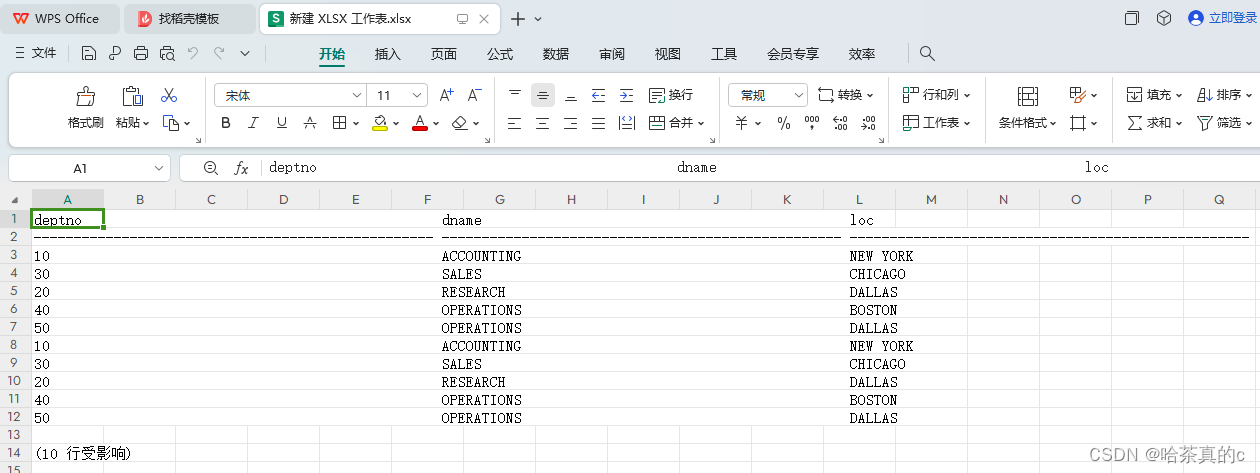
可以看到Excel文件中出现了数据,但是这些数据无法分析(无效数据),将这些数据删除就可以正常进行导入导出。
代码如下所示:
import pyodbc
import pandas as pd
# 创建连接字符串
conn_str = (
r'DRIVER={SQL Server Native Client 10.0};'
r'SERVER=BF-202403241716;'
r'DATABASE=scott;'
r'Trusted_Connection=Yes;'
)
# 建立连接
cnxn = pyodbc.connect(conn_str)
# 创建游标对象
cursor = cnxn.cursor()
# 执行SQL查询
query = "SELECT * FROM dbo.salgrade"
cursor.execute(query)
# 获取查询结果
data1 = cursor.fetchall()
print(type(data1))
print(data1)
# 获取列名
columns1 = [column[0] for column in cursor.description]
print(type(columns1))
print(columns1)
# 将元组列表展开为一维数组
data1 = [list(item) for item in data1]
print(type(data1))
print(data1)
# 将结果转换为DataFrame
df1 = pd.DataFrame(data1, columns=columns1)
print(df1)
# 将数据写入Excel文件
df1.to_excel('output.xlsx', index=False)
# 关闭数据库连接
cursor.close()
cnxn.close()
数据库是:SQL Sever 2008 R2 所以这里采用的连接方式是SQL Sever Native Client 10.0 如果是更新的版本应该是16或者其他
(可以问问ChartGPT)
# 创建连接字符串
conn_str = (
r'DRIVER={SQL Server Native Client 10.0};'
r'SERVER=BF-202403241716;'
r'DATABASE=scott;'
r'Trusted_Connection=Yes;'
)
具体的服务器和数据库按照自己的来,这里我SQL Sever通过验证的方式是Windows验证,所以这里r'Trusted_Connection=Yes;' 如果有用户密码,请使用用户密码的方式登录。
# 将元组列表展开为一维数组 data1 = [list(item) for item in data1] print(type(data1)) print(data1)
<class 'list'> [(null, 700, 1200), (null, 1201, 1400), (null, 1401, 2000), (null, 2001, 3000), (null, 3001, 9999)] <class 'list'> [[1, 700, 1200], [2, 1201, 1400], [3, 1401, 2000], [4, 2001, 3000], [5, 3001, 9999]] grade losal hisal 0 1 700 1200 1 2 1201 1400 2 3 1401 2000 3 4 2001 3000 4 5 3001 9999
需要将元组列表展开为一维数组
原因:data1 是一个包含元组的列表,每个元组都是一个行,但是传递给DataFrame的每行数据应该是一维的,如果不进行转换,那么传递的数据就是二维的
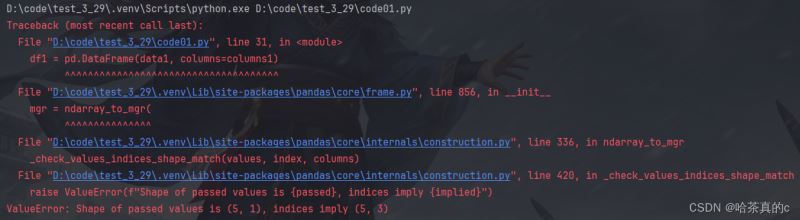
会出现如下类型不匹配的报错==(解决了半天,还是有点不理解)==
import pyodbc import pandas as pd # 假设data是cursor.fetchall()返回的结果,它是一个包含元组的列表 data = [(null, 700, 1200), (null, 1201, 1400), (null, 1401, 2000), (null, 2001, 3000), (null, 3001, 9999)] print(type(data)) print(data) # 获取列名 columns = ['grade', 'losal', 'hisal'] # 确保这些列名与您的表中的列名相匹配 print(type(columns)) print(columns) # 将结果转换为DataFrame df = pd.DataFrame(list(data), columns=columns) print(df)
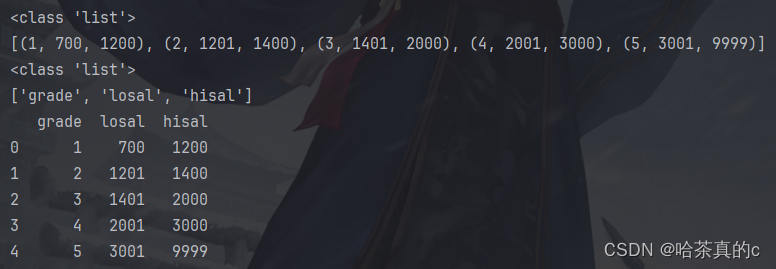
code2当中代码如上,同样还是一个包含元组的列表,但是就是可以转换成DataFrame的形式==(很奇怪啊)==
如果直接从官网进行下载的话,速度可能会很慢,而且有时候还会断开连接,所以可以选择一些国内的镜像网站
pip install some-package -i https://pypi.tuna.tsinghua.edu.cn/simple
以下这种方式就很慢:
(.venv) PS D:\code\test_3_29> pip install openpyxl Collecting openpyxl Downloading openpyxl-3.1.2-py2.py3-none-any.whl.metadata (2.5 kB) Collecting et-xmlfile (from openpyxl) Downloading et_xmlfile-1.1.0-py3-none-any.whl.metadata (1.8 kB) Downloading openpyxl-3.1.2-py2.py3-none-any.whl (249 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 250.0/250.0 kB 547.4 kB/s eta 0:00:00 Downloading et_xmlfile-1.1.0-py3-none-any.whl (4.7 kB) Installing collected packages: et-xmlfile, openpyxl Successfully installed et-xmlfile-1.1.0 openpyxl-3.1.2
成功结果如下:
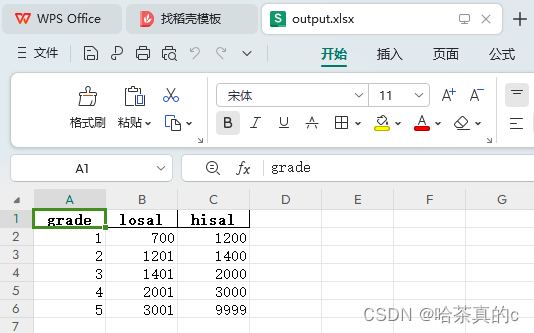
以上就是SQL Server将数据导入导出到Excel表格的全过程的详细内容,更多关于SQL Server数据导入导出到Excel的资料请关注插件窝其它相关文章!