如果不整活,那就是浪费生命
如果你想筛选出age大于等于18,小于等于30的行:
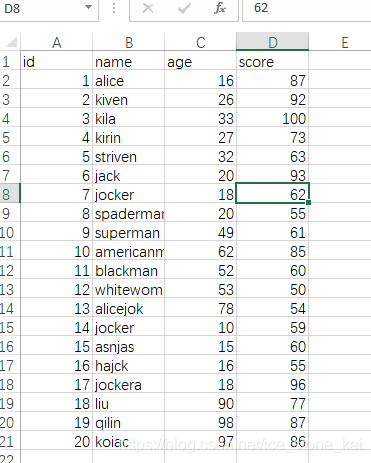
如果在mysql中整这种活很容易,用个where就可以了
在pandas中也有相当于where作用的语法,loc
import pandas as pd
stu = pd.read_csv("data/student.csv", index_col='id')
# 留下18<=年龄<=30
def age_18_to30(a):
return 18 <= a <= 30
# 留下 85<=score
def level_a(s):
return 85 <= s
# 使用loc会生成一个新的series
stu = stu.loc[stu['age'].apply(age_18_to30)]
# 或者用下lambda表达式:
# stu = stu.loc[stu['age'].apply(lambda a:18<=a<=30)]
print(stu)
结果:
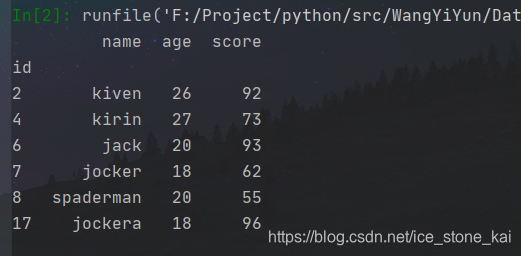
age大于等于18,小于等于30且分数大于等于85:
代码:
import pandas as pd
stu = pd.read_csv("data/student.csv", index_col='id')
# 留下18<=年龄<=30
def age_18_to30(a):
return 18 <= a <= 30
# 留下 85<=score
def level_a(s):
return 85 <= s
stu = stu.loc[stu['age'].apply(age_18_to30)].loc[stu['score'].apply(level_a)]
print(stu)
结果:

其中,获取莫一列,我们一直使用的是stu['age'],这个还可以写为:stu.age
然后就整活成功了!
文件:
F:\Project\python\src\WangYiYun\DataAnalysis\19_.py
完整代码:
# @DATE : 2021-1-2
# @TIME : 16:13
# @USER : kirin
import pandas as pd
stu = pd.read_csv("data/student.csv", index_col='id')
# 留下18<=年龄<=30
def age_18_to30(a):
return 18 <= a <= 30
# 留下 85<=score
def level_a(s):
return 85 <= s
# 使用loc会生成一个新的series
# stu = stu.loc[stu['age'].apply(age_18_to30)]
stu = stu.loc[stu['age'].apply(age_18_to30)].loc[stu['score'].apply(level_a)]
# 或者不使用 stu['age'] :
# stu = stu.loc[stu.age.apply(age_18_to30)].loc[stu.score.apply(level_a)]
# 使用lambda表达式:
# stu = stu.loc[stu.age.apply(lambda a: 18 <= a <= 30)].loc[stu.score.apply(lambda s: 85 <= s)]
# 代码太长回个车:(空格+反斜线+回车)
# stu = stu.loc[stu.age.apply(lambda a: 18 <= a <= 30)]. \
# loc[stu.score.apply(lambda s: 85 <= s)]
print(stu)
以上为个人经验,希望对您有所帮助。