alter table table_name drop primary key; alter table table_name add column column2 varchar(10) NOT NULL COMMENT 'column2' AFTER column2; alter table table_name add constraint user_test primary key(column_list);
使用CREATE语句创建索引:
CREATE INDEX index_name ON table_name(column_name1,column_name2);
CREATE UNIQUE INDEX index_name ON table_name(column_name);
CREATE PRIMARY KEY INDEX index_name ON table_name(column_name);
使用ALTER TABLE语句创建索引:
alter table table_name add index index_name (column_list);
alter table table_name add unique index_name (column_list);
alter table table_name add primary key (column_list);
alter table table_name add fulltext index_name (column_list);
该语句指定了索引为 fulltext。
drop index index_name on table_name; alter table table_name drop index index_name; alter table table_name drop primary key;
alter table table_name rename index old_index_name to new_index_name;
alter table table_name drop index old_index_name alter table table_name add index new_index_name(column_list)
使用 show index 命令来列出表中的相关的索引信息。
可以通过添加 \g 来格式化输出信息。
show index from table_name \g
1. 概念
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。可以得到索引的本质:索引是排好序的快速查找数据结构。一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
2.优势
3.劣势
4.使用原则
5. mysql索引结构
6. 哪些情况需要创建索引
7. 哪些情况不需要创建索引
8. 创建索引的语句
CREATE TABLE table_name[col_name data type] [unique|fulltext][index|key][index_name](col_name[length])[asc|desc]
9. 删除索引的语句
DROP INDEX 索引名 ON 表名; ## 删除book表中的名称为BkNameIdx的索引 DROP INDEX BkNameIdx ON book;
10. 查看表的索引
## 查看表的索引 SHOW INDEX FROM book;
MySQL中分为:普通索引,唯一索引,主键索引,组合索引,和全文索引。
1. 普通索引
是最基本的索引,它没有任何限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。。
它有以下几种创建方式:
# 1.直接创建索引
CREATE INDEX index_name ON table(column(length))
# 2.修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
# 3.创建表的时候同时创建索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
INDEX index_name (title(length))
)
# 4.删除索引
DROP INDEX index_name ON table2. 唯一索引
与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
它有以下几种创建方式:
# 1.创建唯一索引
CREATE UNIQUE INDEX indexName ON table(column(length))
# 2.修改表结构
ALTER TABLE table_name ADD UNIQUE indexName ON (column(length))
# 3.创建表的时候直接指定
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
UNIQUE indexName (title(length))
);3. 主键索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。
一般是在建表的时候同时创建主键索引:
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) NOT NULL ,
PRIMARY KEY (`id`)
);4. 组合索引
指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。
使用组合索引时遵循最左前缀集合
#添加组合索引 ALTER TABLE `table` ADD INDEX name_city_age (id,name,age); #创建组合索引 CREATE TABLE tab3( id INT(4) NOT NULL, name CHAR(20) NOT NULL, age INT(3) NOT NULL, info VARCHAR(255), INDEX multiIdx(id,name,age) );
最左前缀:组合索引遵从了最左前缀,利用索引中最左边的列集来匹配行,这样的列集称为最左前缀。例如,这里由id、name和age3个字段构成的索引,索引行中就按id/name/age的顺序存放,索引组合中的字段可以是(id,name,age)、(id,name)或者(id)。如果要查询的字段不构成最左面的前缀原则,那么就不会用索引,比如,age或者(name,age)组合就不会使用索引查询。
5. 全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。
fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。
fulltext索引配合match against操作使用,而不是一般的where语句加like。
它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。
值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。
# 1.创建表的适合添加全文索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
FULLTEXT (content)
);
# 2.修改表结构添加全文索引
ALTER TABLE article ADD FULLTEXT index_content(content)
# 3.直接创建索引
CREATE FULLTEXT INDEX index_content ON article(content)1. 概念
Explain(查看执行计划),使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。
分析你的查询语句或是表结构的性能瓶颈。
2. 功能
3. 使用方法
Explain+SQL语句,例如
# 创建唯一索引 CREATE TABLE tab1( id INT(5) NOT NULL, name CHAR(20) NOT NULL, UNIQUE INDEX uniqId(id) ); # 查看索引使用信息 EXPLAIN SELECT * FROM tab1 WHERE id = 1;

4.执行计划包含的信息

id: select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
select_type:查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询
table:显示这一行的数据是关于哪些表的。
type:显示的是访问类型,是较为重要的一个指标
结果值从最好到最坏依次是:system>const>eq_ref>ref>range>index>All
一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys:显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出。但不一定被查询实际使用。
key:实际使用的索引。如果为NULL,则没有使用索引。查询中若使用了覆盖索引,则该索引仅出现在key列表中,不会出现在possible_keys列表中。(覆盖索引:查询的字段与建立的复合索引的个数一一吻合)
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好。key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。查询中与其它表关联的字段,外键关系建立索引。
rows:根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数。
Extra:包含不适合在其他列中显示但十分重要的额外信息。
#创建表的SQL语句
CREATE TABLE article(
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
author_id INT(10) UNSIGNED NOT NULL,
category_id INT(10) UNSIGNED NOT NULL,
views INT(10) UNSIGNED NOT NULL,
comments INT(10) UNSIGNED NOT NULL,
title VARBINARY(255) NOT NULL,
content TEXT NOT NULL
);
INSERT INTO article(author_id,category_id,views,comments,title,content)
VALUES(null,1,1,1,'1','1'),(null,2,2,2,'2','2'),(null,3,3,3,'3','3');在没有创建索引的时候,使用explain查看执行计划
# 查询category_id=1 且comments>1的情况下,views最多的article_id EXPLAIN SELECT id,author_id FROM article WHERE category_id=1 AND comments>1 ORDER BY views DESC LIMIT 1;
结论:type是ALL,最坏的情况,extra中出现了using filesort,也是最坏的情况,必须进行优化
![]()
#开始优化 #创建索引 #alter table article add index idx_article_ccv(category_id,comments,views); CREATE INDEX idx_article_ccv ON article(category_id,comments,views); #第二次explain EXPLAIN SELECT id,author_id FROM article WHERE category_id=1 AND comments>1 ORDER BY views DESC LIMIT 1;
![]()
type变成了range,这是可以忍受的,但是extra里using filesort是无法接受的。
但是已经创建了索引,为什么没有用?因为按照Btree索引的工作原理,先降序category_id,如果遇到相同的category_id,再排序comments,如果遇到相同的comments,再排序views。
当comments字段在联合索引中处于中间位置时,因comments>1条件是一个范围值,故MySQL无法利用索引再对后面的views部分进行检索,即range类型查询字段后面的索引无效。
#删除第一次创建的索引 DROP INDEX idx_article_ccv ON article; #第2次新建索引 CREATE INDEX idx_article_cv ON article(category_id,views); #第3次explain EXPLAIN SELECT id,author_id FROM article WHERE category_id=1 AND comments>1 ORDER BY views DESC LIMIT 1;
![]()
结论:type变成ref,extra中的using filesort也消失了,结果非常理想。
以具体的案例说明失效的情况,首先先创建员工表和索引:
#创建员工表
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(24) NOT NULL DEFAULT "" COMMENT '姓名',
age INT NOT NULL DEFAULT 0 COMMENT '年龄',
pos VARCHAR(20) NOT NULL DEFAULT "" COMMENT '职位',
add_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
) CHARSET utf8 COMMENT '员工记录表';
INSERT INTO staffs(NAME,age,pos,add_time) VALUES('z3',22,'manager',NOW()),('july',23,'dev',NOW()),('2000',23,'dev',NOW());
#创建索引
ALTER TABLE staffs ADD INDEX idx_staffs_nameAgePos(NAME,age,pos);1.联合索引(符合索引)不使用第一部分
创建联合索引,但是没有遵循最左前缀法则,则会出现索引失效的情况。
如果索引了多列,要遵守最左前缀法则。
指的是查询从索引的最左前列开始并且不跳过索引中的列。(带头大哥不能死,中间兄弟不能断哈哈哈)
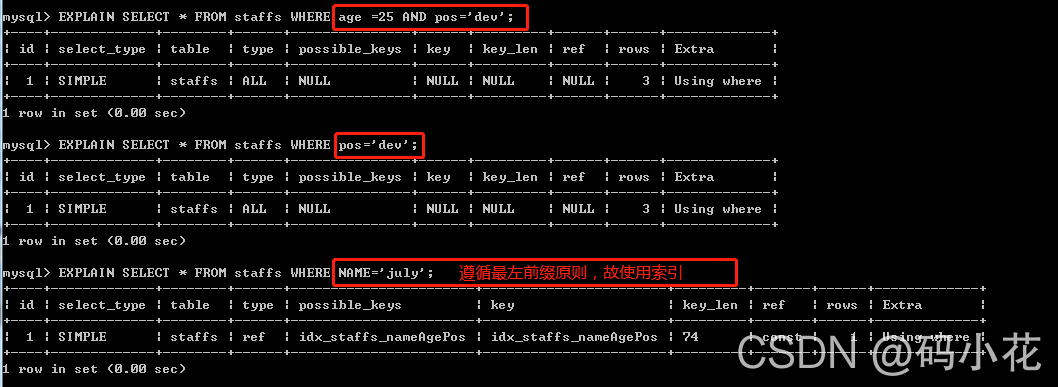
2.where条件有数学运算或函数

3.mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
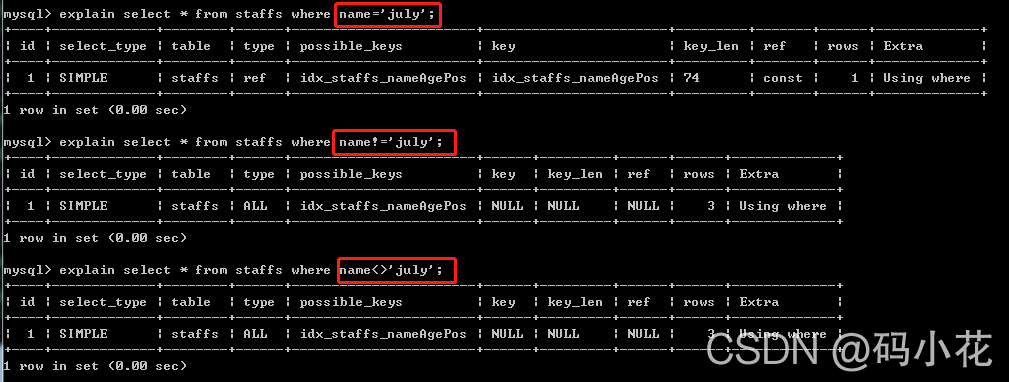
4. mysql在使用 is null,is not null也无法使用索引

5. like以通配符开头(‘%abc…’)mysql索引失效会变成全表扫描的操作,当%加在右边时可以使用
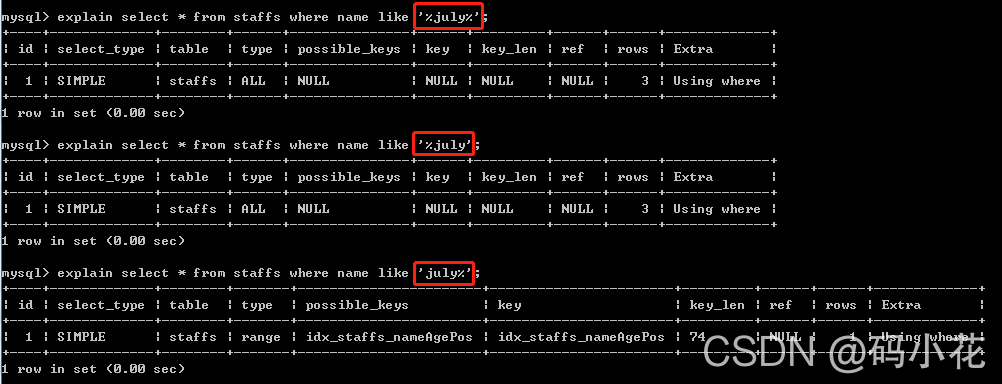
6. 字符串不加单引号索引失效
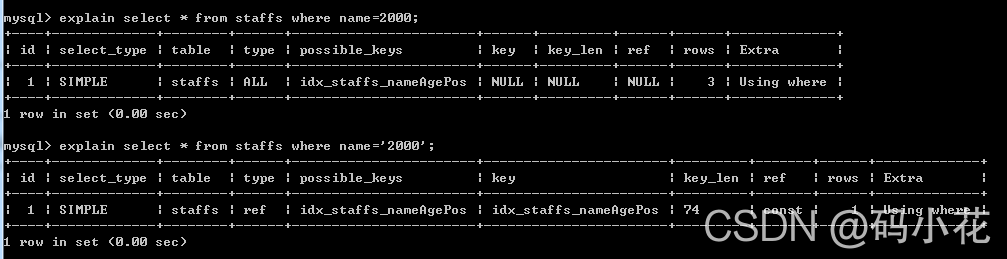
7. where条件使用or

注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
以上为个人经验,希望对您有所帮助。