MySQL对于被驱动表的关联字段没索引的关联查询,一般都会使用 BNL 算法。如果有索引一般选择 NLJ 算法,有 索引的情况下 NLJ 算法比 BNL算法性能更高。
关系型数据库还有一个重要的概念:Join(连接)。使用Join有好处,也会坏处,只有我们明白了其中的原理,才能更多的使用Join。切记不可以:
业务之上,再复杂的查询也在一个连表语句中完成。
敬而远之,DBA每次上报的慢查询都是连接查询导致的,我再也不用了。
我们先来创建两个简单的表,再初始化一些数据
CREATE TABLE t1 (m1 int, n1 varchar(1)); CREATE TABLE t2 (m2 int, n2 varchar(1)); INSERT INTO t1 VALUES(null, 'a'), (2 , 'b') ,(3 ,'c') ; INSERT INTO t2 VALUES(2 , 'b'), (3 , 'c '),(4 , 'd');
从本质上来说,连接就是把各个表的数据都取出来进行匹配,t1 和 t2 的两个表连接起来就是这样的:
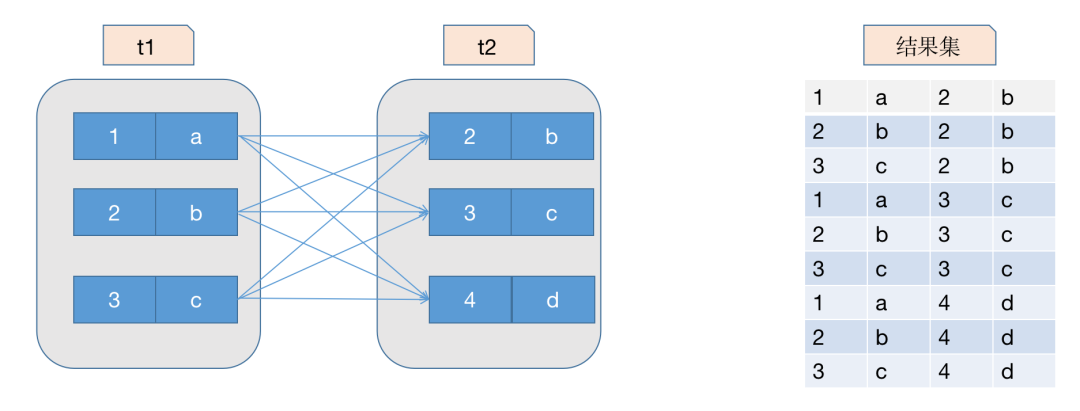
连接语法:
select * from t1, t2;
如果乐意,我们可以连接任意数量的表。但是如果不加任何限制条件的话,这个数据量是非常大的,我们现实中使用都是会加上限制条件的。
我们来看下下面这条语句
select * from t1,t2 where t1.m1 > 1 and t1.m1 = t2.m2 and t2.n2 = 'c';
这个连接查询的执行过程大致如下
首先确定第一个需要查询 表称为驱动表(t1)
步骤1中从驱动表 (t1) 中每获得一条记录,都要去被驱动表 (t2) 中查询匹配。
从上面的步骤,可以看出上述的连表查询我们需要查询一次t1,两次t2。也就是说,两表的连接查询中,需要查询一次驱动表,被驱动表需要查询多次。
这里需要注意下,并不是将所有满足条件的驱动表记录先查询出来放到一个地方,然后再去被驱动表中查询,(如果满足条件的驱动表中的数据非常多,那要需要多大的内存呀。) 所以是每获得一条驱动表记录就去被驱动表中查询。
我们再来创建两个表,并插入一些数据
CREATE TABLE student (
number INT NOT NULL Auto_increment comment'学号',
name varchar (5) COMMENT '姓名',
major varchar (30) comment '专业',
PRIMARY KEY (number));
CREATE TABLE score (
number INT comment'学号',
subject varchar (30) COMMENT '科目',
score TINYINT comment '成绩',
PRIMARY KEY (number, subject));
INSERT INTO `student` (`number`, `name`, `major`)
VALUES ('20230301', '小赵', '计算机科学');
INSERT INTO `student` (`number`, `name`, `major`)
VALUES ('20230302', '小钱', '通信');
INSERT INTO `student` (`number`, `name`, `major`)
VALUES ('20230303', '小孙', '土木工程');
INSERT INTO `score` (`number`, `subject`, `score`)
VALUES ('20230301', '高等数学', '60');
INSERT INTO `score` (`number`, `subject`, `score`)
VALUES ('20230301', '英语', '70');
INSERT INTO `score` (`number`, `subject`, `score`)
VALUES ('20230302', '高等数学', '80');
INSERT INTO `score` (`number`, `subject`, `score`)
VALUES ('20230302', '英语', '90');如果我们想把所有的学生的成绩都查出来,只需要这样执行:
select s1.number, s1.name, s1.major, s2.subject, s2.score from student as s1 , score as s2 where s1.number = s2.number;
有个问题就是小孙因为某些原因没有参加考试,所以在结果表中没有对应 的成绩记录。如果老师想查看所有学生的考试成绩,即使是缺考的学生 他们的成绩也应该展示出来。
为了解决这个问题,就有了内连接和外连接的概念:
MySQL 中,根据选取的驱动表的不同,外连接可以细分为
当我们使用外连接的时候 有时候我们也不想把驱动表的全部记录都加入到最后的结果集中,这个时候我们就要使用过滤条件了。
所以上述的需求我们可以左查询这样来做:
select s1.number, s1.name, s1.major, s2.subject, s2.score from student as s1 left join score as s2 on s1.number = s2.number;
语法:
#左连接 select * from t1 left join t2 on '连接条件' where '普通过滤条件' #右连接 select * from t1 right join t2 on '连接条件' where '普通过滤条件'
内连接的另一种写法,也是常用写法
select s1.number, s1.name, s1.major, s2.subject, s2.score from student as s1 inner join score as s2 where s1.number = s2.number;
语法:
select * from t1 inner join t2 on '连接条件' where '过滤条件'
上述说了这么多,知识简单回顾一下连接,左连接,右连接这些概念。
接下来我们重点说一下 MySQL 采用了什么样的算法来进行表与表之前的连接。
前面我们已经介绍过了执行连接查询的大致步骤了,我们再来简单回顾一下
整个过程就像是一个嵌套循环,所以这种连接方式称为 嵌套循环连接 ,这是最简单也是最笨的一种连接查询算法。
大致处理过程如下:
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}需要注意的是对于获套循环连接算法法来说,每当我们从驱动表中得到了一条记录时,就根据这条记录立时到被驱动表中查询一次,如果得到了匹配的记录, 就把组合后 的记录发送给客户端,然后再到驱动表中获取下一条记录。这个过程将重复进行。
这个是我们比较熟悉的方式,也是相对来说最有用的方式,在被驱动表上创建合适的索引,只返回必要的字段等都可以起到一些优化的作用。
每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取出一条与其匹配,匹配结束后清楚内存,然后再从驱动表中加载一条记录,然后把被驱动表的记录加载到内存匹配,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读这个表好多次,这个IO的代价就非常大了。所以我们得想办法,尽量减少被驱动表的访问次数,于是就出现了下面这种方式。
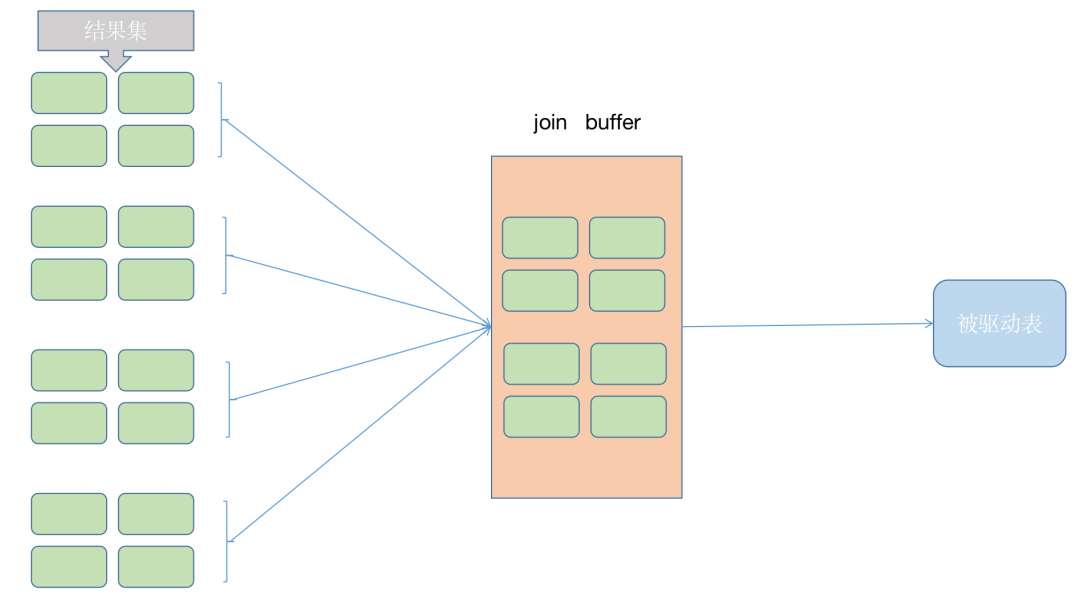
不再是逐条获取驱动表的数据,而是一块一块的获取,引入join buffer 缓冲区, 将驱动表join 相关的部分数据列(大小受join buffer的限制)缓存到 join buffer中,然后开始扫描被驱动表,被驱动表的每一条记录一次性和join buffer中所有的驱动表记录进行匹配(内存中操作)。将简单嵌套循环中的多次比较合并成一次,降低了备驱动表的访问频率。
这里缓存的不只是关联表的列,select后面的列也会缓存起来。所以查询的时候尽量减少不必要的字段,可以让join buffer中可以存放更多的列。
join_buffer_size的最大值在32为系统中可以申请4G,在64为操作系统中可以申请大于4G的空间。
MySQL对于被驱动表的关联字段没索引的关联查询,一般都会使用 BNL 算法。如果有索引一般选择 NLJ 算法,有 索引的情况下 NLJ 算法比 BNL算法性能更高。
超过三个表禁止 join。【阿里巴巴JAVA开发手册】
需要 join 的字段,数据类型必须绝对一致;【阿里巴巴JAVA开发手册】
多表关联查询时,保证被关联的字段需要有索引,尽量选择NLJ算法。【阿里巴巴JAVA开发手册】
小表驱动大表,写多表连接sql时如果明确知道哪张表是小表可以用straight_join写法固定连接驱动方式,省去mysql优化器自己判断的时间
以上为个人经验,希望对您有所帮助。