存储过程: 可以理解为完成特定功能的一组 SQL 语句集,存储在数据库中,经过第一次编译,之后的运行不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来调用存储过程。
创建存储过程可以有两种方式:一是在 SSMS 中界面操作创建存储过程,而后修改其中的 SQL 语句及存储过程名称;二是通过命令行直接编写创建存储过程。
在操作之前,得要有一个数据库和数据库中将要使用存储过程查询或操作的数据表,这里以 MyDBDemo 数据库为例,其中有一个 sys_user 的用户数据表。
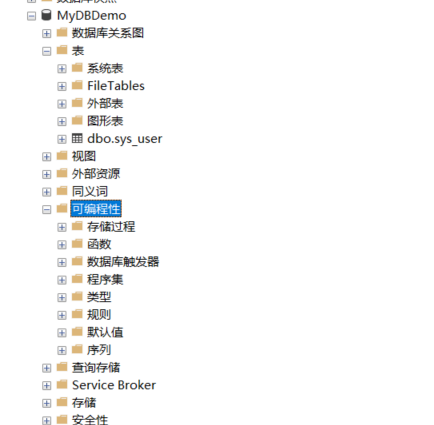
界面鼠标操作创建存储过程方便快捷,一些基础的脚本不需要手动编写,由 SSMS 自动生成。
步骤: 展开数据库中的【可编程性】,在【存储过程】上鼠标单击右键出现弹出菜单,点击【存储过程】即可弹出新的查询窗口,里面有一些默认的 SQL 脚本。
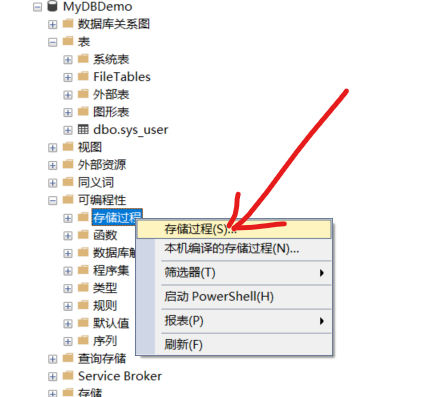
软件自动生成的存储过程创建脚本,现在可以基于此修改存储过程中的内容了。
说明: 从 第 1 行到 20 行不需要关注,这些都是一些设置和注释说明,第 21 行到 33 行才是存储过程的主要内容。下面将通过代码逐行介绍这些命令。
CREATE PROCEDURE <Procedure_Name, sysname, ProcedureName> -- 这一行表示存储过程的名称, '<>' 是占位符,将其替换为存储过程的名称
-- 以下列出存储过程的参数以及返回参数,这是设置存储过程有哪些参数和返回什么数据
<@Param1, sysname, @p1> <Datatype_For_Param1, , int> = <Default_Value_For_Param1, , 0>,
<@Param2, sysname, @p2> <Datatype_For_Param2, , int> = <Default_Value_For_Param2, , 0>
AS
BEGIN -- 从这里开始就是存储过程的主体部分
-- 这里面的内容就是 SQL 语句集,可以放置许多的 SQL 增删查改等操作脚本
END -- 这里结束存储过程,表示存储过程的 SQL 集在这里结束
脚本创建存储过程就是自行编写基础的创建存储过程的语句,如上所示代码中的内容都是自行手动编写,然后执行脚本即可创建好这个存储过程。
如下创建存储过程的脚本,是传入用户的数据参数,插入到数据库中,而后再查询出来展示,详细讲解请看注释,SQL 脚本如下所示:
CREATE PROCEDURE InsertUser -- 这里存储过程的名称为‘InsertUser'
-- 输入参数有userno、pwd、username、role、email,输出参数有 count
-- 输入输出参数的名称前面必须加上 ‘@' ,表示其是一个变量。
@userno nvarchar(50), --输入参数,用户编码
@pwd nvarchar(50), -- 输入参数,登录密码
@username nvarchar(50), -- 输入参数,用户姓名
@email nvarchar(50), -- 输入参数,用户邮箱
@count int output-- 输出参数,当前数据表中的总数据条数,这里输出参数采用 ‘output' 标识
AS
BEGIN -- 从这里开始就是存储过程的主体部分
-- 这里插入一条数据到数据表中,数据内容来源于存储过程中传入的内容,其中用户角色字段 ‘[role]' 设置默认值为 ‘admin'
INSERT INTO [dbo].[sys_user] ([userno],[pwd],[username],[role],[email])
VALUES (@userno,@pwd,@username,'admin',@email);
-- 查询出数据表
select * from [dbo].[sys_user];
-- 返回值总条数查询
select @count = @@ROWCOUNT;
END -- 这里结束存储过程,表示存储过程的 SQL 集在这里结束
存储过程的使用需要采用关键字 EXEC 加上存储过程名称,而后跟随参数的方式。
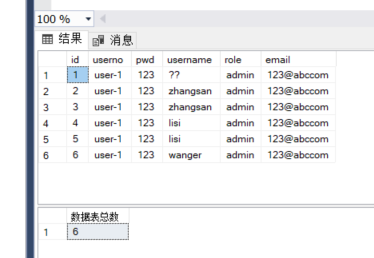
DECLARE @pdCount INT; -- 定义返回值参数 -- 通过 exec <存储过程名称> <参数列表> 调用存储过程 exec [dbo].[InsertUser] @userno='user-1',@pwd='123',@username='wanger',@email='123@abccom',@count=@pdCount output select @pdCount as '数据表总数' -- 查询出返回值中的内容
执行结果如下所示:
1、存储过程加快系统运行速度,存储过程只在创建时编译,以后每次执行时不需要重新编译。
2、存储过程可以封装复杂的数据库操作,简化操作流程,例如对多个表的更新,删除等。
3、可实现模块化的程序设计,存储过程可以多次调用,提供统一的数据库访问接口,改进应用程序的可维护性。
4、存储过程可以增加代码的安全性,对于用户不能直接操作存储过程中引用的对象,SQL Server可以设定用户对指定存储过程的执行权限。
5、存储过程可以降低网络流量,存储过程代码直接存储于数据库中,在客户端与服务器的通信过程中,不会产生大量的T_SQL代码流量。
1、数据库移植不方便,存储过程依赖与数据库管理系统, SQL Server 存储过程中封装的操作代码不能直接移植到其他的数据库管理系统中。
2、不支持面向对象的设计,无法采用面向对象的方式将逻辑业务进行封装,甚至形成通用的可支持服务的业务逻辑框架。
3、代码可读性差,不易维护。不支持集群。
为什么需要存储过程:效率高、降低网络流量、复用性高、可维护性高、安全性高。
到此这篇关于SQL server创建存储过程的文章就介绍到这了,更多相关SQL server创建存储过程内容请搜索插件窝以前的文章或继续浏览下面的相关文章希望大家以后多多支持插件窝!