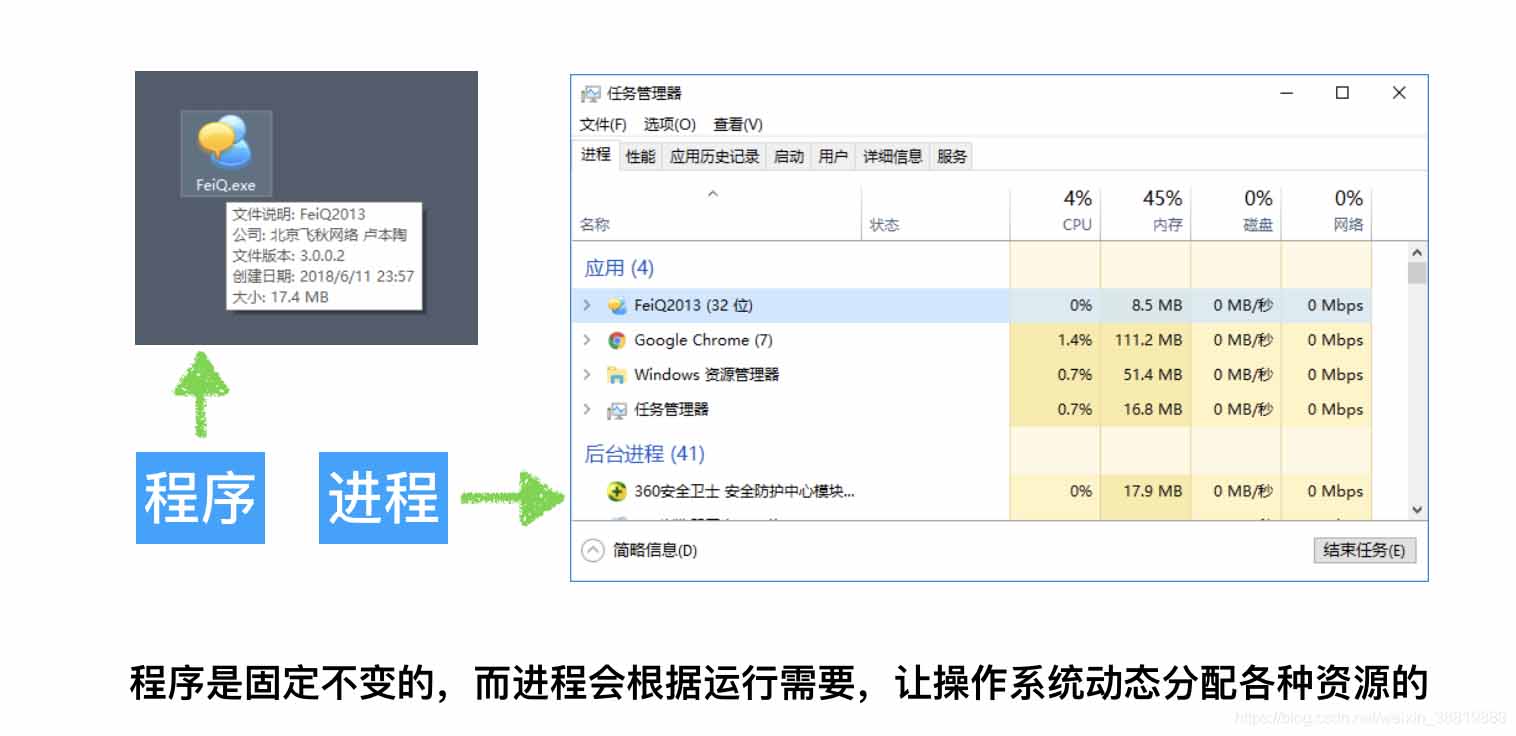
进程是资源分配的最小单位,程序隔离的边界。
CPU的时间片轮转,在不同的时间段切换执行不同的进程,但是切换进程是比较耗时的;就引来了轻量级进程,也就是所谓的线程,一个进程中包括多个线程(代码流,其实也就是进程中同时跑的多个方法体)
工作中,任务数往往大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致了有了不同的状态

multiprocessing模块就是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情。
方法说明:
创建子进程跟创建线程十分类似,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动。
Process语法结构如下: Process([group [, target [, name [, args [, kwargs]]]]])
Process创建的实例对象的常用方法:
Process创建的实例对象的常用属性:
代码示例:
import multiprocessing
import time
def work1():
for i in range(10):
print("work1----", i)
time.sleep(0.5)
if __name__ == '__main__':
# 创建进程
# 1. 导入 multiprocessing 模块
# 2. multiprocessing.Process() 创建子进程
# 3. start() 方法启动进程
p1 = multiprocessing.Process(group=None, target=work1)
p1.start()
for i in range(10):
print("这是主进程", i)
time.sleep(0.5)
multiprocessing.current_process()

有两种方法可以获取
1)multiprocessing.current_process().pid
2)使用import os模块的getpid()
import multiprocessing
import time
import os
def work():
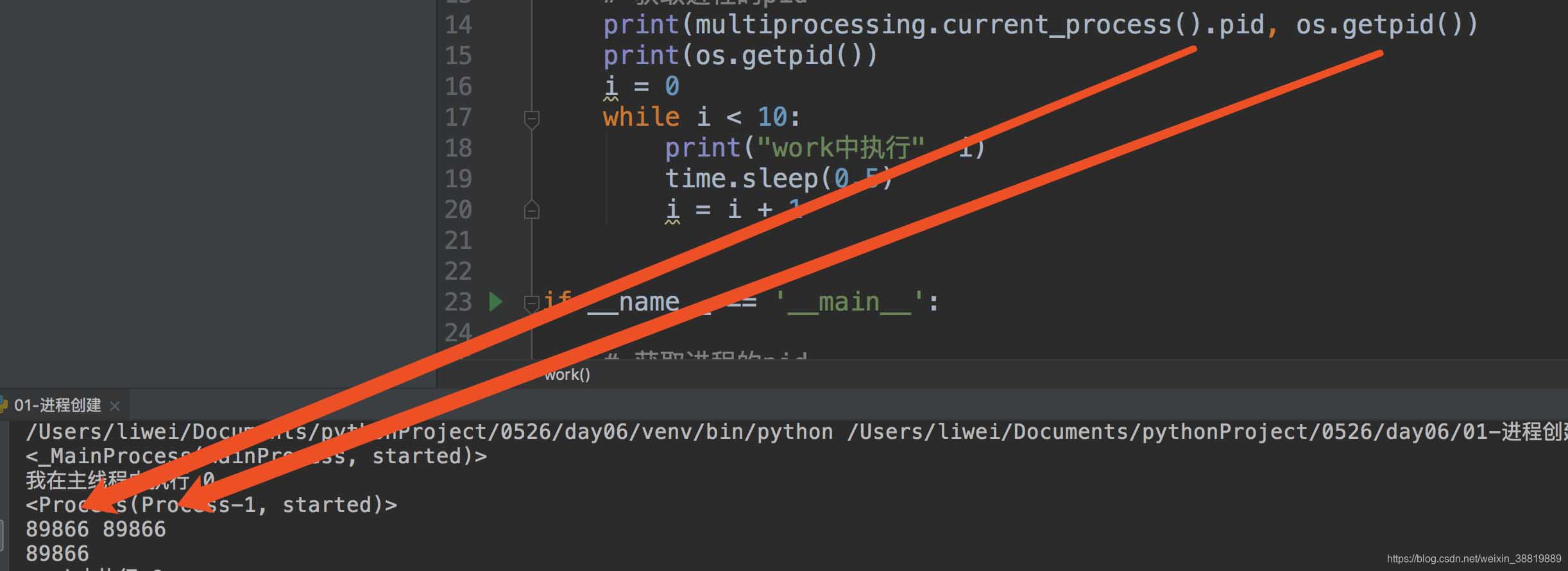
# 获取进程的名称
print(multiprocessing.current_process())
# 获取进程的pid
print(multiprocessing.current_process().pid, os.getpid())
i = 0
while i < 10:
print("work中执行", i)
time.sleep(0.5)
i = i + 1
if __name__ == '__main__':
# 获取进程的pid
print(multiprocessing.current_process())
# 创建子进程
process1 = multiprocessing.Process(group=None, target=work)
process1.start()
i = 0
while i < 10:
print("我在主线程中执行",i)
time.sleep(0.3)
i = i + 1
获取父id: getppid() 获取父进程id
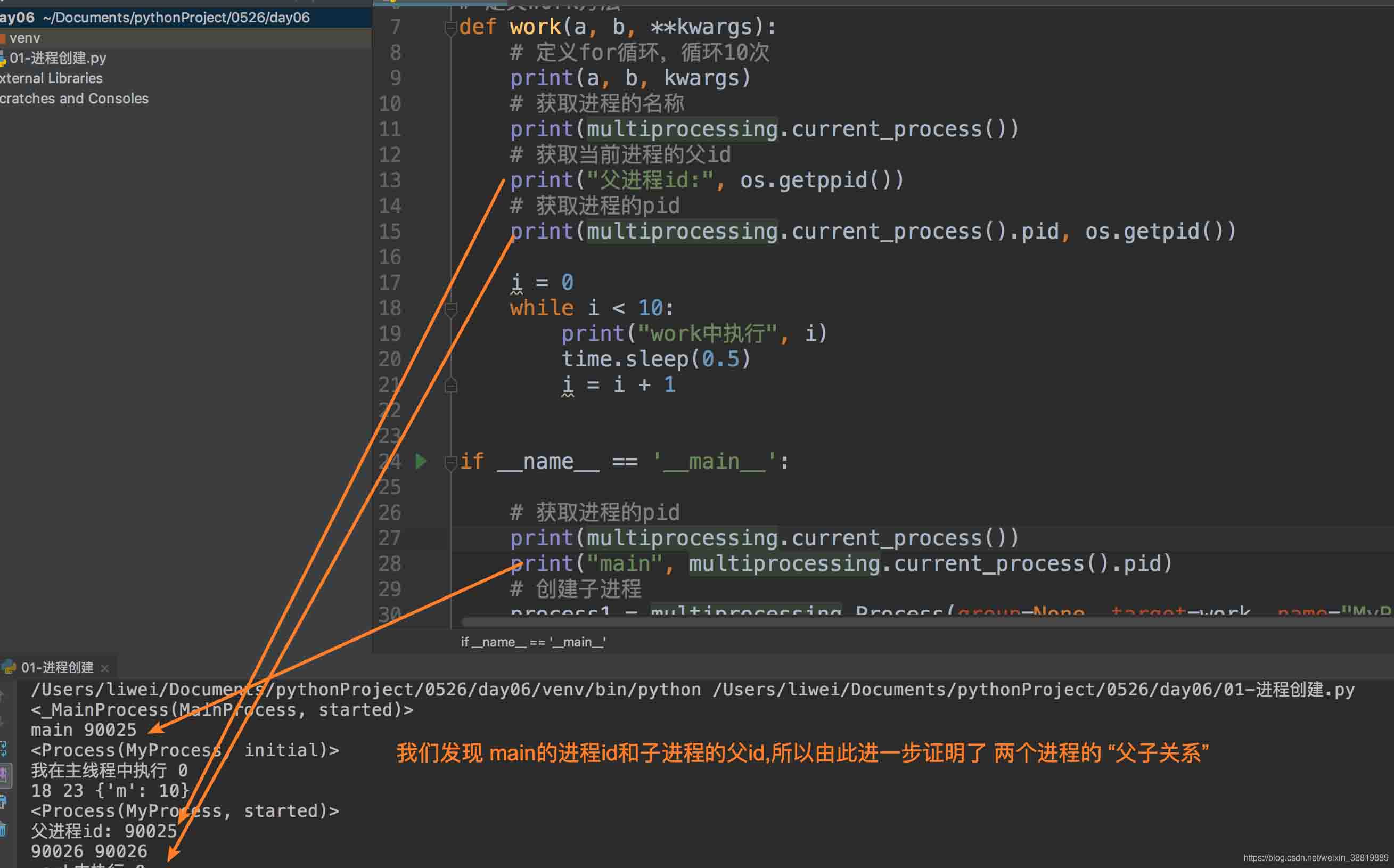
给子进程传递参数方法和给子线程传递参数方法基本一致!
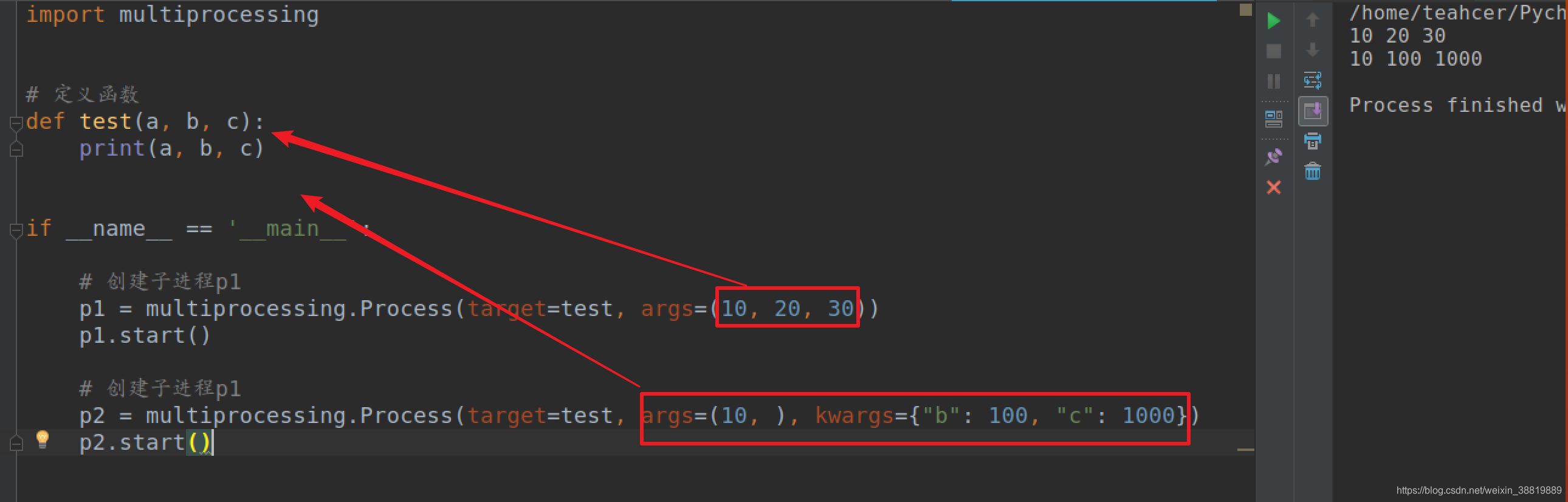
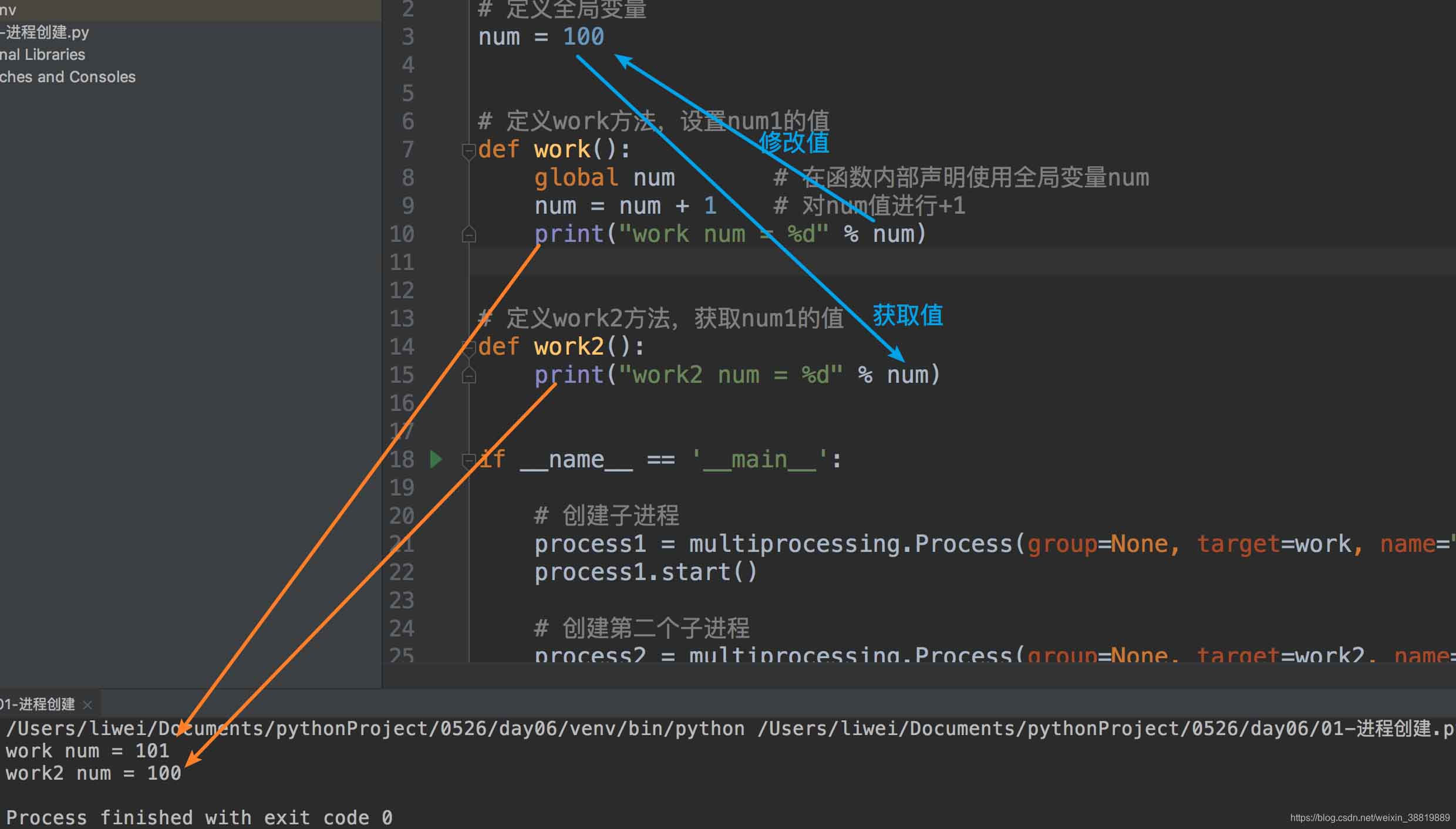
import multiprocessing
# 定义全局变量
num = 100
# 定义work方法,设置num1的值
def work():
global num # 在函数内部声明使用全局变量num
num = num + 1 # 对num值进行+1
print("work num = %d" % num)
# 定义work2方法,获取num1的值
def work2():
print("work2 num = %d" % num)
if __name__ == '__main__':
# 创建子进程
process1 = multiprocessing.Process(group=None, target=work, name="MyProcess")
process1.start()
# 创建第二个子进程
process2 = multiprocessing.Process(group=None, target=work2, name="MyProcess2")
process2.start()
运行结果:
work num = 101
work2 num = 100
由运行结果可以看出,work函数对num1的修改,在work2中并没有获取到,而还是原来的100,所以,进程之间是不能够共享变量的
import multiprocessing
import time
def sub_process():
for i in range(10):
print("子进程运行中", i)
time.sleep(0.5)
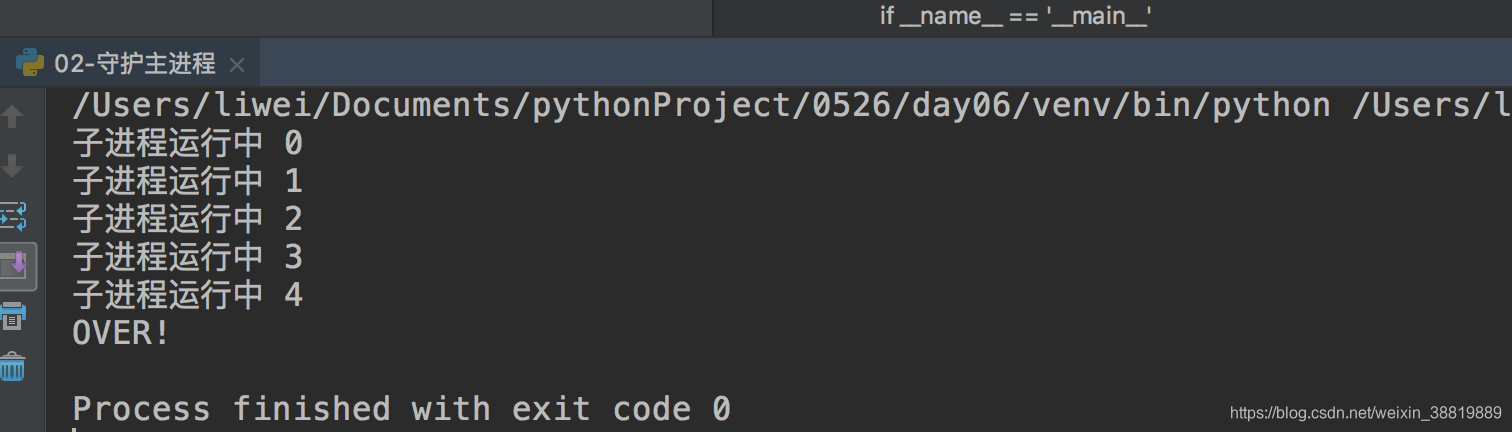
if __name__ == '__main__':
# 创建子进程
p1 = multiprocessing.Process(group=None, target=sub_process, name="p1")
# 设置守护主进程
# 第一种方式:
# p1.daemon = True
# 第二种方式(最好在退出exit()前一句使用):
# p1.terminate()
# 启动
p1.start()
time.sleep(2)
print("OVER!")
p1.terminate()
exit()
以上为个人经验,希望对您有所帮助。